
AI Is Accelerating At Accelerating Rates
Breaking down the Qwen2.5-VL Technical Report & discussing implications

We have breaking developments from China.
As I called out in the post below, DeepSeek is in danger of being taken out by dark horse Alibaba and their Qwen series of models.

Well this week Qwen dropped a doozy of a model that has taken over the throne in terms of combined visual and language-based benchmarks.
Just like humans need to see with our eyes and reason using language inside our minds… we are starting to optimize models around this architecture.
Very exciting. Of course, they also released a wonderful paper we are going to unpack here.
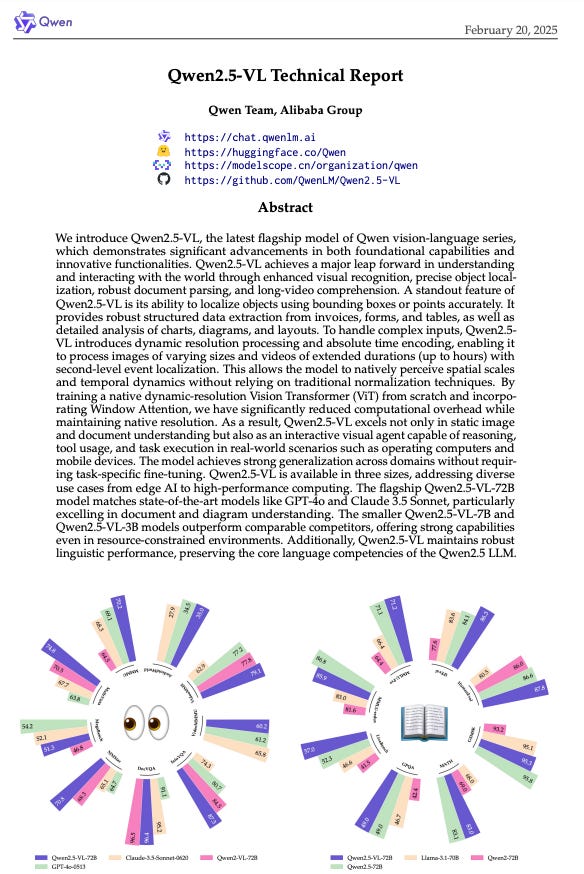
Alibaba's Qwen Team introduces Qwen2.5-VL, a vision-language model excelling in visual recognition, object localization, document parsing, and video understanding. This model uses dynamic resolution processing and time encoding to handle diverse inputs and leverages window attention for efficiency. Qwen2.5-VL comes in three sizes, with the 72B parameter model rivaling GPT-4o and Claude 3.5 Sonnet, especially in document understanding, while smaller v…
