
Did DeepSeek Get DeepSeeked by Alibaba?

There are still so many open questions about the resources DeepSeek deployed to create their incredible new model — but no one is doubting the brilliance of their training methodologies and overall approach. Even if you write-off DeepSeek’s performance as nothing more than RL with a few efficiency techniques compounded against each other you cannot deny the response from giants like Microsoft and upstarts like Perplexity. Both are hosting the new darling model: DeepSeek-V3.
The customer has spoken, too. Just after its release on Jan. 20 the DeepSeek AI assistant became the top app in Apple’s Top Free App category.
And before OAI, Google or Microsoft (or Mistral.. remember them?) could clap back my X feed exploded with word of a new offering from Alibaba’s Qwen team.
Welcome to the world, Qwen 2.5-Max.
Bring out the bar charts! Let’s see who’s taller?
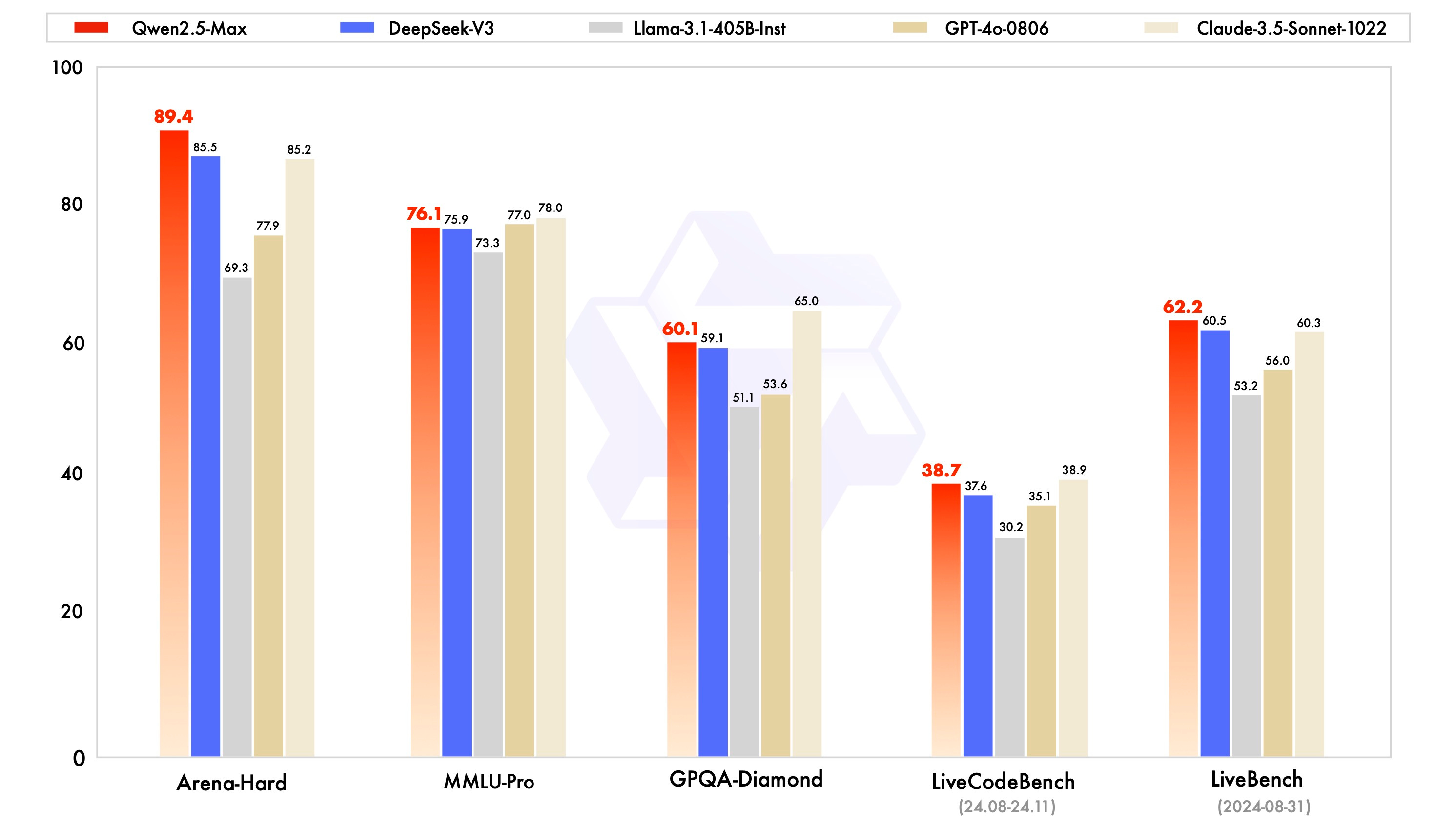
According to this graphic on Qwen team’s blog and the quote below, there has been a change in the power rankings due to new dual curated SFT (Supervised Fine-Tuning) and Reinforcement Learning from Human Feedback (RLHF) approach to training.
Qwen 2.5-Max is the smartest in the room, according to this blog post written by the team behind Qwen. It appears to outperform DeepSeek-V3 in every measure.
From the site:
It is widely recognized that continuously scaling both data size and model size can lead to significant improvements in model intelligence. However, the research and industry community has limited experience in effectively scaling extremely large models, whether they are dense or Mixture-of-Expert (MoE) models. Many critical details regarding this scaling process were only disclosed with the recent release of DeepSeek V3. Concurrently, we are developing Qwen2.5-Max, a large-scale MoE model that has been pretrained on over 20 trillion tokens and further post-trained with curated Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) methodologies.
That bolded part (my edit by the way) stood out because it indicates collaboration or a form of information sharing / communication between the DeepSeek and Alibaba Qwen team. Very interesting.
Suddenly two different teams debut this same underlying approach of SFT and RL?
Both from China? In the same week?
This is pure speculation but the wording above and the timing of events is being studied by a lot of people right now. National power is being influenced by these outcomes.
What an incredible age to be alive and building intelligent systems.
Taking Apart Qwen & Comparing to DeepSeek
Let’s review the last technical report from this group which was published in December of 2024 but updated with a v2 in the first week of January 2025.
People often miss the updates on these papers.
That’s a shame, because the research teams read the feedback to their papers. They read counter-papers. They go to conferences and talk to their peers.
…and then they get smarter.
So they enrich their methods. Perhaps it’s in data preprocessing, or model architecture, or training techniques… there’s a lot of surface area for improvement in ML. DeepSeek clearly tweaked at every knob they could reach in search for efficiency and alpha of any sort.
Let’s take Qwen down to the studs first and then we’ll compare their training methods to DeepSeek.
