
Predicting Medicine Into Existence - Part IV

I had so much fun with this competition.
The winner SHOCKED the world and rocketed from nearly 900th place to win the whole thing. With $50,000 up for grabs that’s a big shakeup.
The data we were all working with represented just 35% of the set. Once the competition ended our models were tested against the remaining data and a private leaderboard was revealed with the true winners.
Here they are:
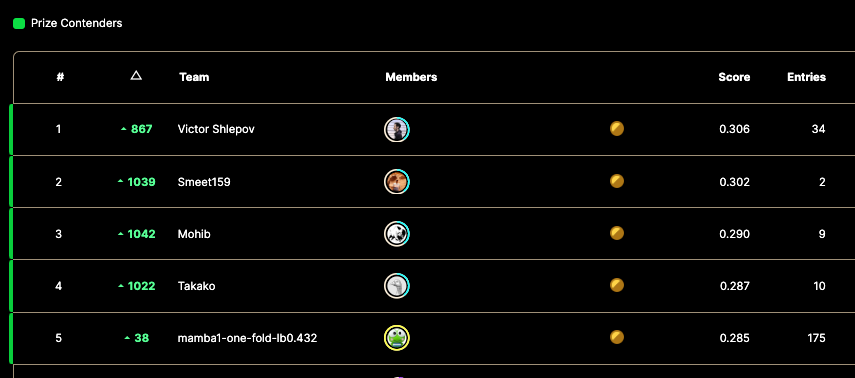
My score jumped up a bit too… but just 22 positions.
I ended up in 1723rd place out slightly more than 9,000 competitors.
