
Open Source Multimodal LLMs Reach New Power Levels

Our world isn’t a corpus of text. It’s filled with sights, sounds and data in all kinds of structures. LLMs are confined to text-only.
This recently released research paper introduces InternVL3, a new generation of open-source Multimodal Large Language Models (MLLMs).
InternVL3 advances the field by proposing a more streamlined and potentially more effective native pre-training paradigm, complemented by carefully chosen architectural tweaks, richer data strategies, and advanced optimization techniques that collectively push the performance boundaries for open-source MLLMs.
The key innovation of InternVL3 is its "native multimodal pre-training" paradigm. Unlike previous methods that typically adapt pre-existing text-only Large Language Models to handle visual inputs through separate, often complex, alignment stages (a "post-hoc" approach) InternVL3 is trained from the pre-training stage using a mix of both pure text data and diverse multimodal data (like image-text pairs) simultaneously. That little twist has made a big impact.

This unified approach is designed to integrate linguistic and visual understanding more deeply and efficiently (sort of like how our brain integrates audio and visual signals) while avoiding the alignment challenges inherent in multi-stage pipelines.
To enhance its capabilities further, InternVL3 incorporates several technical advancements. It uses Variable Visual Position Encoding to better handle long sequences of multimodal inputs, allowing for more flexible processing of visual information within the text context. The model also benefits from advanced post-training techniques, including Supervised Fine-Tuning with higher-quality, more diverse data covering areas like tool use and GUI operations, and Mixed Preference Optimization, which helps align the model's outputs with desired responses by learning from both positive and negative examples. Additionally, test-time scaling strategies, using a critic model to select the best response from multiple generated outputs, are employed to boost reasoning performance.
We’ve discussed SFT in detail here before:

Back to the breakthrough. Let’s contextualize this performance and then explore the implications this has for AI.
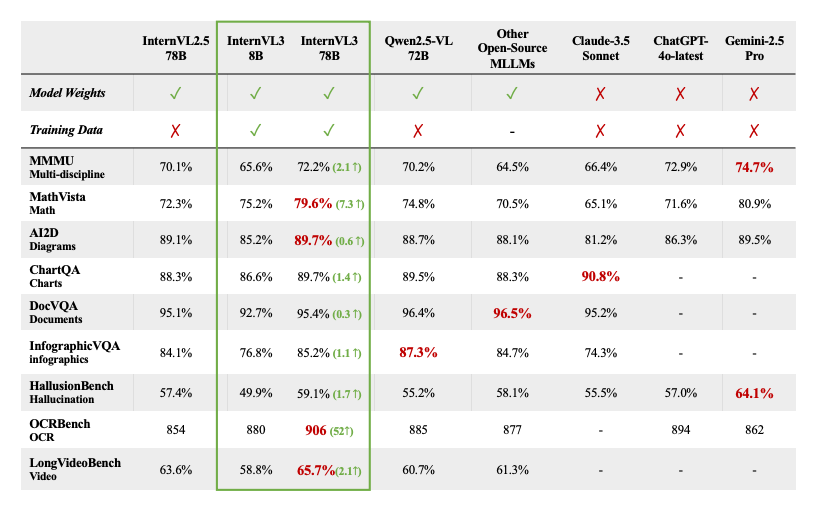
The paper presents extensive evaluations showing that InternVL3, particularly the 78-billion parameter version (InternVL3-78B), achieves state-of-the-art performance among open-source MLLMs on numerous benchmarks, including complex reasoning (MMMU), math, document understanding, and video comprehension. Its performance is shown to be highly competitive with leading proprietary models like ChatGPT-40, Claude 3.5 Sonnet, and Gemini 2.5 Pro. The authors emphasize their commitment to open science by planning to release the model weights and training data to encourage further research.
Science and technology are locked in an accelerating dance and open source increases the pace of the song much faster than centralized R&D / Big Tech alone.
