
The Trouble with Tokens
The Trillion-Dollar Stopgap

In Silicon Valley, Richard Hendricks’ “middle-out” compression was a platform-level breakthrough.
The incumbent Hooli was just brute-forcing the problem by throwing massive, expensive hardware at the wall to get incremental gains in streaming and storage. Pied Piper’s breakthrough wasn’t just “10% better” it was a fundamental, 10x shift that made the old way look stupid. It was a new primitive that promised to build a “new internet.”

A cutting edge research paper released 5 days ago is the exact same story, but for the generative AI bottleneck.
This research paper introduced a new approach called CALM. Think of CALM as the Pied Piper algorithm.
For years, the entire industry has been stuck in a brute-force “token-by-token” loop. We’re the new Hooli, throwing trillions at more GPUs just to speed up this “one word fragment at a time” process. It’s an insane computational bottleneck.
Instead of just optimizing the old way, they challenged the premise. They built a new architecture, just like “middle-out,” that provides near-lossless compression (over 99.9% accuracy). But they’re not compressing files; they’re compressing meaning.
I will explain what this means more deeply in a moment. For now, focus on the implications.
This is an industry-altering breakthrough.
The plot of Silicon Valley was about the fight to turn that brilliant algorithm into a product. This paper is the raw, academic breakthrough itself. It’s the “algorithm” that obsoletes the old stack. It’s the foundation for a “new internet” of generative AI, and it just handed the blueprint to every builder who’s smart enough to see it.
The Trouble With Tokens
For the last five years we’ve been in awe of LLM.
But it hasn’t been all good.
Builders, investors, and operators have been held hostage by a single, maddening bottleneck: the “token-by-token” generation process.
We’re all building and funding these god-level, 100-billion-parameter large language models, models with the computational power to simulate entire worlds, and we’re forcing them to do one thing: guess the next word fragment.
It’s insane. It’s a “profound mismatch” between the model’s immense representational power and the laughably simple, low-information task we’re forcing it to perform. This one, sequential bottleneck is the single reason AI inference is so slow, so expensive, and so fundamentally limited. We’re driving a fleet of monster trucks to haul pebbles, one by one.
The entire industry has been trying to fix this. We’ve thrown trillions of dollars at bigger GPUs, faster interconnects, and clever quantization tricks, all to speed up this “next-token” prediction.
We’ve been optimizing around the bottleneck.
Not removing it.
The problem, we all thought, was intractable. To increase the “semantic bandwidth” of each step you’d need to grow the model’s vocabulary exponentially. The final layer would become computationally impossible. We were stuck, locked in a discrete prison of our own making.
Then, last week, a paper from a team at Tencent and Tsinghua University landed on arXiv. It’s called Continuous Autoregressive Language Models (CALM), and it’s not just another incremental improvement.
It’s a complete jailbreak.

From Bricks to Blueprints
The CALM team didn’t try to optimize the bottleneck. They challenged the fundamental assumption that created it: the discrete token.
Their “what if” was simple and brilliant: What if we stop predicting tokens and start predicting ideas?
Maybe that’s abstract. Let’s take it my world, engineering.
What if we predict a single continuous vector that represents a whole chunk of tokens?
The old way is like a telegraph operator describing a picture by tapping out one letter at a time. CALM is like sending a high-resolution JPEG. The semantic bandwidth is in a different league.
This isn’t a theoretical wish. They built it. And as a builder myself, the sheer elegance of the engineering stack they created is what gets my blood pumping.
Inside a New Kind of AI Mind

CALM works in two stages:
Step One | The Compressor: A “Perfect” API for Meaning
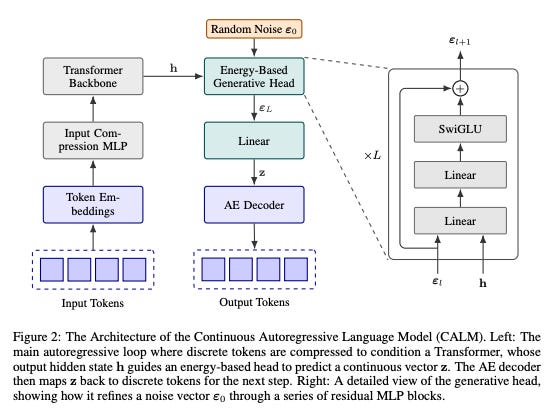
First, they built a “high-fidelity” auto-encoder. This thing is a masterpiece of practical engineering.
It compresses a chunk of
Ktokens (say,K=4tokens, like “The cat sat on”) into a single, dense continuous vector.It reconstructs that vector back into the exact original 4 tokens with over 99.9% accuracy.
Think about that. They’ve essentially built a perfect, two-way translation layer between messy, human-readable text and a clean, machine-readable vector. It’s a “bijective mapping” or put simply, a lossless API for meaning. Best of all, this auto-encoder is tiny. Its computational overhead is “nearly negligible” compared to the main LLM.
Step Two | The New Task: K-Times Faster Generation
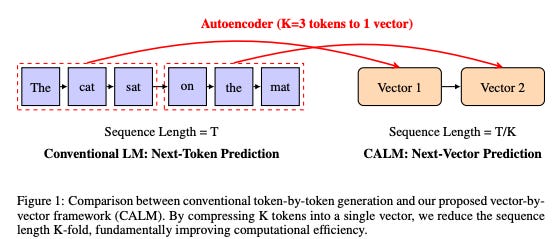
With this compressor in hand, the LLM’s job just got K-times easier. Instead of a T-length sequence of tokens, the model now operates on a sequence of vectors. Its only job is to predict the next vector.
This is the core of the 100x opportunity.
But this is also where my operator brain went into overdrive. This should be impossible. How do you predict a single vector from an infinite continuous space? You can’t run a “softmax” function over an uncountable set. The standard LLM toolkit doesn’t work.
So, the CALM team had to invent an entirely new “likelihood-free” toolkit from scratch. This toolkit is the most valuable part of this paper.
A New Way to Train
They threw out cross-entropy loss. Instead, they use a lightweight “Energy Transformer” trained with an “energy loss”. Instead of asking, “What’s the probability of this vector?” (which is intractable), it asks, “How close is my batch of generated vectors to the batch of target vectors?”. It’s a sample-based distance metric, and it’s what enables efficient, single-step generation. No iterative diffusion nonsense.
A New Way to Evaluate
They created BrierLM , a new metric based on a classic scoring rule that is also likelihood-free. You can run it just by looking at samples from the model. Here’s the genius part: they proved it has a near-perfect rank correlation (-0.991 Spearman) with the old metric. They built a new yardstick that is 100% compatible with the old one, ensuring we’re not flying blind.
A New Way to Sample
They even reinvented temperature sampling. Since you can’t tweak softmax logits, they built a new “approximate” sampling algorithm (Algorithm 2). And get this: by tuning the batch size (N) of this sampler, you can perfectly replicate the accuracy-diversity curve of traditional temperature (T) . It’s a new knob that gives you the exact same control.
This isn’t a theory. It’s a complete, end-to-end, battle-tested system.
And the punchline? It works.
A 371M-parameter CALM model achieves comparable performance to a Transformer baseline, but requires 44% fewer training FLOPs and 34% fewer inference FLOPs.
They didn’t just find a new path up the mountain. They built a high-speed rail line that goes straight through it.
Platforms, Primitives, and the New Compute Frontier
This is where we, as investors and builders, need to pay close attention. The alpha in this paper isn’t just “cheaper FLOPs.” That’s the symptom. The disease this cures is the industry’s lock-in to discrete text.
The real opportunity is that CALM has created a new, universal “primitive” for AI.
This paper establishes the Continuous Vector as the new platform primitive. We are witnessing the pivot point from a world of discrete tokens (language) to a world of continuous vectors (ideas).
The auto-encoder they built is the new API.
Think about what Stripe did for payments. Before Stripe, every startup had to build its own brittle, complex, custom-coded payment gateway. After Stripe, a few lines of code gave you a robust, scalable, world-class payments platform.
CALM’s auto-encoder is the “Stripe for Meaning.” It’s a robust, plug-and-play compressor that turns messy, multi-token text chunks into clean, single-vector representations.
This platform shift changes so much about the state of compute:
The Compute Market: This paper fundamentally re-writes the performance-compute frontier. For the last five years, the only scaling axis we had was “add more parameters and pray.” The CALM framework introduces “semantic bandwidth” (the chunk size, K) as a powerful new scaling axis. For any given compute budget, we now have a new set of levers to pull. We can build bigger, smarter models (more parameters) that run at the same cost as today’s smaller, dumber ones.
The Incumbents: This is an extinction-level event for any company whose entire value proposition is “we make token-by-token generation 5% faster.” The entire “inference optimization” stack, from speculative decoding to custom kernels, is about to be rebuilt from the ground up, or thrown out entirely.
The MLOps Stack: The MLOps toolkit (monitoring, evaluation, fine-tuning) is built on a foundation of probability distributions and logits. None of that works here. The authors explicitly state that foundational techniques like RLHF (which needs log-probs) and knowledge distillation (which needs KL divergence) are now intractable . BrierLM is the first shot, but this is a completely greenfield opportunity.
We need a new suite of tools for a “likelihood-free” world.
This paper isn’t just about faster inference. It’s a philosophical shift.
It’s the moment AI stops mimicking the artifacts of human thought (words) and starts modeling the medium of it (concepts). We’re finally moving from digital telegraphy to analog, high-bandwidth thought.
This is the jump from processing language to processing meaning.
The builders who get this will own the next decade.
Friends: in addition to the 17% discount for becoming annual paid members, we are excited to announce an additional 10% discount when paying with Bitcoin. Reach out to me, these discounts stack on top of each other!
Thank you for helping us accelerate Life in the Singularity by sharing.
I started Life in the Singularity in May 2023 to track all the accelerating changes in AI/ML, robotics, quantum computing and the rest of the technologies accelerating humanity forward into the future. I’m an investor in over a dozen technology companies and I needed a canvas to unfold and examine all the acceleration and breakthroughs across science and technology.
Our brilliant audience includes engineers and executives, incredible technologists, tons of investors, Fortune-500 board members and thousands of people who want to use technology to maximize the utility in their lives.
To help us continue our growth, would you please engage with this post and share us far and wide?! 🙏