
LLMs Turbocharge Reinforcement Learning
AI Research Paper Breakdown Deep Dive - #1

Our recently launched series where we unpack cutting edge research papers in AI / ML has been a big hit.
Thank you for the positive feedback and for all of the subscriptions.
I was most surprised by the generous wave of paid subs. In light of all these new paying members it’s important we release a paper breakdown deep dive every week.
How else can we keep up with the Great Acceleration?
Everything is going faster at faster rates.. with rapidly generating new surface area for scientific discovery, technological development and feats of engineering.
The Singularity including AGI gets closer and closer with every novel architecture, each design generation… think of it, every day more minds join the global effort to build skyscrapers of machine intelligence - each contributing their experience, viewpoint, unique approach to problem solving and much more.
The fun thing is how democratized this is. We have individual geniuses finally able to link up thanks to the internet and social media… and we have massive research houses filled with big minds backed by bigger balance sheets.
Let’s look at a recent contribution from one of the latter, the Microsoft Research team in Asia.
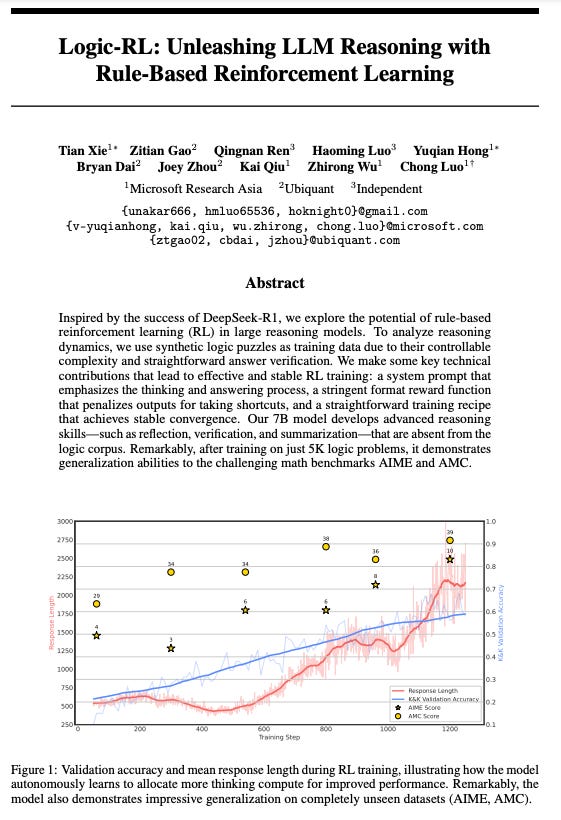
Normally, I start by geeking out about how they built their model, and then we look at the results.. and then we talk about the implications for the field.
This time we’re going straight to the results.
A lot of the AI community was shocked by the Microsoft researchers’ results, the Logic-RL framework demonstrates a remarkable ability to generalize to out-of-distribution (OOD) scenarios… that’s a fancy way of saying it can do stuff it wasn’t trained to do.
That’s the G in AGI.
That indicates we are getting closer to AGI.
The 7B model, after training on only 5,000 logic problems, improved by 125% on the AIME and 38% on the AMC benchmarks, suggesting the development of abstract problem-solving schemata rather than domain-specific pattern matching. This is cross-domain generalization aka the good stuff.
How do we know it’s really general intelligence and not a lucky or engineered result?
