
Intelligence Keeps Finding Cheaper Ways to Emerge

The universe does not care about effort.
It cares about output. It cares about torque. It cares about leverage.
Look at the evolution of machine intelligence. It is not a story of magic. It is a story of thermodynamic ruthlessness.
Intelligence is an engine. And intelligence keeps finding cheaper ways to emerge.
You are a biological engine operating in a landscape of infinite data. Your career is not a journey. Your career is an algorithm. You are processing inputs, updating your weights, and attempting to generate a high-yield output through brute force.
Brute force does not scale. Grinding is a failure of architecture. When you rely on friction to generate heat, you eventually burn out the engine.
To achieve absolute sovereignty, you must study the architecture of artificial intelligence. The trajectory of escaping local optima in silicon is the exact blueprint for escaping the middle class in carbon.
If we map out the architectural paradigm shifts in deep learning, we see a clear, undeniable pattern. It is the systemic removal of computational bottlenecks to allow intelligence to scale cheaply.
It’s the pursuit of maximum leverage. My favorite!
The Fully Connected Era
Look at the pre-2010s, we had The Fully Connected Neural Network.
Every neuron connected to every other neuron. Every node had to communicate with the entire system.
It was universally expressive. It could theoretically learn anything.
But it was computationally disastrous.
When you connect everything to everything, the noise overwhelms the signal. The system drowns in its own internal friction. The mathematical reality was the vanishing gradient problem. The signal died before it could update the core weights.
This is the state of the modern knowledge worker.
You are fully connected. You are trying to process every email, every trend, every notification, and every possible skill. You are acting as a dense layer in a corporate neural network.
Stop trying to process the entire board.
When your architecture is fully connected, your cognitive load is maximized, but your actual leverage is zero. You are a generalist in a system that only rewards specific, concentrated torque. You hit a local optimum early. You plateau. Your personal gradient vanishes.
The Spatial Compression Era
Then came the first great escape.
We realized we did not need to look at everything at once. We did not need dense, chaotic connections.
We built spatial compression.
By using shared weights and sliding windows (convolutions, the C in CNN) we made spatial intelligence computationally cheap. We restricted the receptive field. We forced the network to look only at local patterns. Edges. Textures. Gradients.
The system learned to extract high-value features with a fraction of the compute.
This is the power of constrained architecture.
It is the ability to filter. It is the ability to isolate. It is the ability to apply the exact same high-leverage mental model across a massive data stream.
You do not need to understand every sector of the economy. You need a specialized filter. You need a cognitive convolution that sweeps across the market, ignoring the noise, and extracting only the alpha.
Find your shared weights. Build a framework. Apply it ruthlessly to the raw data of your industry.
Mastering space by focusing on smaller areas made sense.
Next, we attempted to conquer time.
The Recurrent Era
We needed to understand sequences. Language. Markets. DNA.
We built the Recurrent Neural Network (RNN) and the LSTM.
To understand the sequence, we used recurrence. The network passed its hidden state forward. It remembered the past to predict the future.
It worked. But its bottleneck was time.
You had to process step A before you could process step B. You had to process word B before word C.
It could not be parallelized. It was entirely sequential.
Think about how this applies to your daily life to put this into perspective.
Look at your income streams. Look at what you do with your time.
Are you operating as an RNN?
If you are trading your time for money, you are a recurrent system. You must process Monday to get paid for Monday. You must process Tuesday to get paid for Tuesday. You cannot parallelize your output.
Your architecture is bottlenecked by the physical rotation of the Earth.
This is the ultimate liability. You cannot build wealth sequentially. You cannot scale sovereignty one hour at a time. The sequential architecture is a trap. It limits your compute.
It limits your yield.
P.s. I talk about building wealth systems and applying technology to wealth engine development and integration at Wealth Systems , check it out:

The Quadratic Death Trap → Why Attention Must Fall
To break the sequential bottleneck, the system evolved. We entered the current dominant paradigm.
The era of Attention, staring the Transformer.
Attention allowed for massive parallelization. It broke the time trap. You could look at the entire sequence at once.
We were told “Attention Is All You Need.”
And for a long time, that worked. It created the LLM revolution. It built the modern AI infrastructure.
But here is the hard truth.
Attention is a thermodynamic dead end. It is a local optimum.
Its fatal flaw is its fundamental math: the mechanism of standard self-attention scales quadratically.
If you double the context length, you quadruple the compute.
Read that again and deeply internalize the problem.
You quadruple the memory requirements. If you want a model to process a book instead of a chapter, the computational cost does not double. It explodes exponentially.
Attention forces every token to look at every other token in the sequence. It calculates a massive, dense matrix of relevance.
It is brilliant… and it is entirely unsustainable.
Look at the modern executive or founder.
You are running a self-attention mechanism on your life. You are trying to hold the entire context window in your active memory. You are calculating the relationship between your product, your marketing, your competitors, your code, and your capital stack, all at once.
As your business grows, your mental compute requirements are squaring.
You are burning out your hardware.
You are hitting the physical limits of your biological RAM.
You cannot scale quadratically. The universe will not allow it. The physics of your brain will throttle you.
We are actively trying to find a cheaper path to emergence. We must escape this trap.
Iterative Denoising
This brings us to the horizon.
The architectural shifts that will define the next decade of capital and compute.
Diffusion models.
Diffusion replaces the sequential prediction engine with something entirely alien. It reframes learning not as next-token prediction, but as iterative denoising.
You do not start from nothing and build sequentially.
You start with complete, chaotic static. You start with maximum entropy.
Instead of calculating attention across all points, a diffusion model learns the exact geometric shape of the data distribution. It learns how to systematically remove the noise. Step by step, the static is stripped away, and the high-fidelity signal emerges.
It is a fundamentally different way for intelligence to model reality.
For continuous data spaces, it is vastly more efficient than attention.
Apply this to your strategic positioning.
Stop trying to predict your next career move sequentially. Stop trying to guess the next word in the sentence.
Start with the absolute endpoint. The sovereign, high-leverage state you demand. Assume the environment is pure noise. Pure chaos.
Your job is not to build from scratch. Your job is iterative denoising.
Look at your daily calendar. Look at your asset allocation. It is full of static. Remove the low-leverage meetings. Strip away the toxic clients. Delete the inefficient workflows.
You do not need to add more features to your life. You need to denoise the system. As you remove the friction, the optimal path naturally emerges.
The Sovereign State Space: Linear Dominance
But what about sequential reasoning? What about logic?
While diffusion conquers continuous space, the architectural war for sequential data is being waged right now.
State Space Models (SSMs). Mamba. Linear Attention.
These are the leading candidates to assassinate standard attention.
Why? Because they solve the paradox of the Transformer.
They achieve the massive parallel training capability we love from Transformers. You can train them on supercomputers at maximum throughput.
But during inference (during execution) they scale linearly.
They compress the entire history of the sequence into a fixed-size hidden state. They do not need to look back at every single token. They maintain a perfectly compressed representation of reality that updates with constant compute time.
They are explicitly designed to be the cheaper way to emerge.
This is the ultimate architectural goal for the human operator.
You must build an SSM architecture for your decision-making.
You must aggressively parallelize your training. Read aggressively. Absorb data streams. Analyze markets. Do this when you are offline, building your mental models.
When a crisis hits, you cannot re-evaluate your entire life’s history.
You cannot calculate an attention matrix across every past mistake and future anxiety.
You must rely on a compressed, fixed-state heuristic. A hardened protocol.
Jocko Willink calls it default aggressive. Taleb calls it antifragility. Naval calls it specific knowledge.
I call it the sovereign state space.
You encounter an input. You filter it through your compressed mental model. You execute the output. Constant time. Low energy. Maximum torque.
The Thermodynamics of Capital and Compute
This progression from Fully Connected Nets to CNNs, from RNNs to Transformers, from Attention to SSMs touches on something deeper than computer science.
It’s the physics of reality.
In information theory, my favorite topic in school, we have the concept of Algorithmic Minimum Description Length.
The best model of data is the one that compresses it the most. The system that understands reality the best is the one that requires the fewest bits to describe it.
As our neural architectures evolve, we are simply finding mathematical shortcuts to compress the universe’s complexity. We are pushing the intelligence into fewer parameters. We are requiring fewer Floating Point Operations Per Second (FLOPs).
This is the Principle of Least Action.
In physics, systems evolve along the path of least resistance. A ball rolls down a hill. Light bends through water to minimize travel time.
If we view intelligence as a physical system processing entropy, the progression of architectures is just the system finding lower-energy states to accomplish the exact same predictive tasks.
“Cheap” is not a derogatory term. In engineering, “cheap” is the highest compliment. “Cheap” means you have eliminated the friction. “Cheap” means you have maximized the leverage.
But “cheap” is always relative to the physics of the underlying hardware.
Matrix multiplication became the dominant paradigm because GPUs existed. We had hardware that was exceptionally good at parallel, dumb calculations. The algorithm evolved to perfectly exploit the physics of the silicon.
The next great architecture will be whatever perfectly exploits the physics of the next generation of hardware. Neuromorphic chips. Optical computing. Quantum gates.
I would bet big on photonics. I think symbols are going to come back “in style” but paired with diffusion or transformers to address the walls we hit with symbols in the 60s (and 90s). Diffusion will be used on the edge due to it’s speed.
The algorithm and the hardware are locked in a co-evolutionary death match.
And the winner will be the approach that uses the “nature of reality” most effectively.
Energy-Based Architecture
Like any good engineer, the universe is lazy.
The universe defaults to high entropy.
The universe relentlessly seeks the lowest possible energy state.
Look at the frontier of machine learning we see Energy-Based Models (EBMs).
An EBM does not blindly predict the next token in a sequence. It does not guess. It maps the entire environment. It assigns a scalar value (think of it like an “energy” level) to every possible configuration of reality.
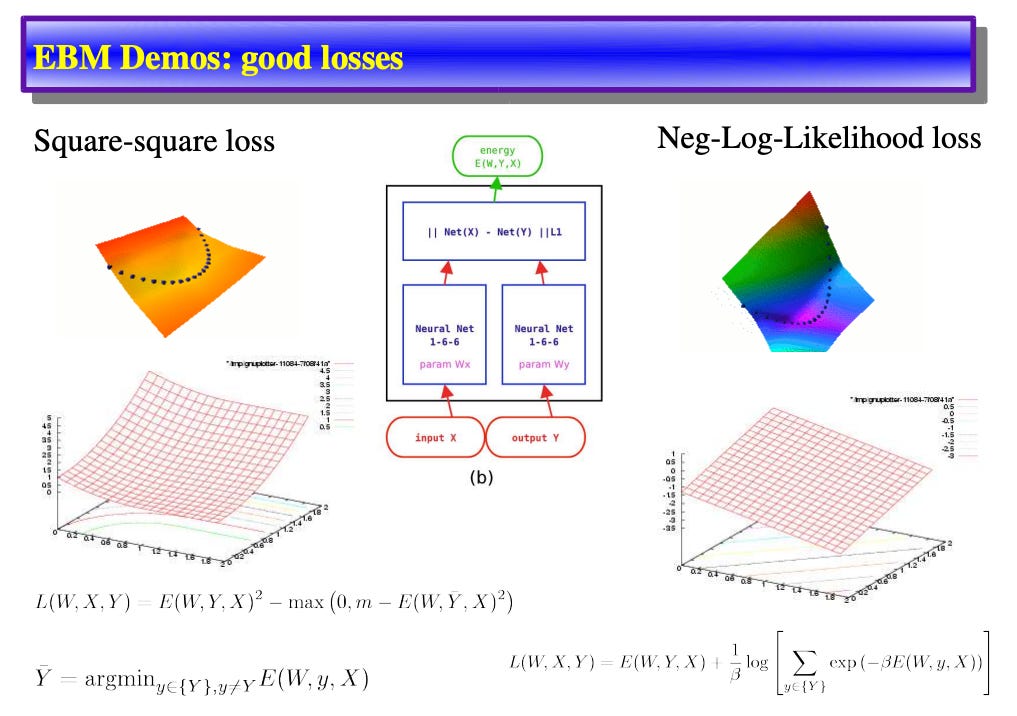
It learns the geometry of the board.
It learns where the friction is.
It learns how to make the correct answer the easiest path.
In an EBM, the probability of any given state occurring is defined by the Boltzmann distribution.
The math is absolute. The lower the energy of a state, the higher the probability that the system will naturally settle there.
When an EBM trains, it shapes the physical topography of its network. It uses “contrastive divergence”. It pushes down on the energy of the correct data. It pulls up on the energy of the noise. It carves a deep valley into the algorithmic landscape.
The model does not try to find the right answer. It simply rolls down the hill.
This is a big leap from the brute-force paradigms of the past. Currently, we force our models to sprint on a treadmill. We feed autoregressive systems trillions of tokens, hoping they memorize the statistical patterns well enough to mimic understanding. It works but it is an uphill battle against complexity. It is computationally exhaustive, treating every new generation as a frantic, forward-facing sprint.
The future of machine learning is not about pushing harder.
It’s about letting gravity do the work.
When we shift from autoregressive guessing to energy-based mapping, we unlock an entirely new tier of reasoning. An EBM doesn’t just generate a plausible string of text it generates a mathematically stable reality. Because it inherently models the constraints of its environment, it becomes uniquely suited for the hardest, most complex physical problems we face.
Imagine the future of robotics. A robot powered by an EBM doesn’t need to calculate every micro-movement of its arm against a vast library of pre-programmed gestures. It understands the “energy” of the physical space. It knows the constraints of gravity, momentum, and friction. It allows its movements to settle into the lowest energy state to achieve its goal, moving with the fluid, effortless grace of biological life.
Imagine materials science and drug discovery. The model intrinsically maps the thermodynamic constraints of molecular bonds, finding the stable folded protein or the perfect zero-carbon catalyst not by brute-force trial and error, but by natural descent.
The answer is found because it is the only logical place for the system to rest.
This is the core of the techno-optimist vision: we are no longer fighting nature to build artificial intelligence. We are finally learning to harness nature’s most fundamental algorithms. For decades, our software architectures were rigid, brittle, and deeply unnatural.
Now, as we transition from spamming tensor math to energy-based architectures, we are building computational systems that mirror the universe itself.
We are moving beyond teaching machines to blindly memorize human output. We are teaching them the physics of existence. By aligning our models with the principles of thermodynamics, we are setting the stage for an intelligence explosion that is less like a frantic, unending calculation, and more like a river finding the sea.
The future of intelligence isn’t a relentless computational grind.
The universe is beautifully, elegantly lazy, and in that laziness, we have found the blueprint for ultimate efficiency.
The hill is carved.
Now, we just let it roll.
Faster, and faster… forever forward into the Singularity.
Friends: in addition to the 17% discount for becoming annual paid members, we are excited to announce an additional 10% discount when paying with Bitcoin. Reach out to me, these discounts stack on top of each other!
Thank you for helping us accelerate Life in the Singularity by sharing.
I started Life in the Singularity in May 2023 to track all the accelerating changes in AI/ML, robotics, quantum computing and the rest of the technologies accelerating humanity forward into the future. I’m an investor in over a dozen technology companies and I needed a canvas to unfold and examine all the acceleration and breakthroughs across science and technology.
Our brilliant audience includes engineers and executives, incredible technologists, tons of investors, Fortune-500 board members and thousands of people who want to use technology to maximize the utility in their lives.
To help us continue our growth, would you please engage with this post and share us far and wide?! 🙏