
How Attention Residuals are Rewiring the Modern LLM

TL;DR
The foundational wiring of large language models just got a massive, long-overdue upgrade. For years, AI architectures relied on standard residual connections which blindly accumulate data layer by layer with fixed unit weights. This uniform aggregation leads to uncontrolled hidden-state growth as the network gets deeper. Now, researchers from the Kimi Team have introduced Attention Residuals. By applying softmax attention across the depth of the network, each layer can now selectively pull exactly the information it needs from previous layers using learned, input-dependent weights. To make this scale, they built Block Attention Residuals to chunk these layers together and drastically reduce memory footprints. The result is an architectural breakthrough that matches the performance of standard models trained with 1.25x more compute.
This is a smarter, leaner, and fundamentally superior way to build a neural network.
The Background
To understand why this is a monumental shift in AI architecture, we have to look at the plumbing of modern neural networks. Standard residual connections are the de facto building block of modern large language models. Originally designed to solve the vanishing gradient problem, they act as a gradient highway. They allow mathematical gradients to bypass complex transformations and flow unchanged through identity mappings. This mechanism is exactly what allows us to train incredibly deep neural networks stably.
However, there is a hidden flaw in the system. When you unroll the mathematics of a standard residual connection, you realize that every single layer receives the exact same uniformly-weighted sum of all prior layer outputs. This means the network’s depth-wise aggregation is governed entirely by fixed unit weights.
Imagine you are at a crowded cocktail party. Every time a new person joins the conversation, they just start shouting their ideas into the group at the exact same volume as everyone else. By the time the tenth person arrives, the noise is deafening. In the world of LLMs, this phenomenon is tied to something called PreNorm. PreNorm is the dominant paradigm for normalizing these models, but its unweighted accumulation causes the magnitudes of hidden states to grow continually with depth. This progressively dilutes the relative contribution of each individual layer.
Because the early-layer information gets buried under a mountain of accumulated data, those early signals cannot be selectively retrieved. To compensate, later layers are forced to learn increasingly larger outputs just to gain influence over the massively accumulated residual signal. This brute-force shouting match destabilizes training and prevents the model from truly leveraging its own depth. Prior attempts to fix this have relied on scaled residual paths or multi-stream recurrences, but these remain tightly bound to the flawed additive recurrence model.
The AI industry has essentially been building taller and taller skyscrapers on top of a foundation that compresses and crushes its lowest floors.
The Main Event
Enter Attention Residuals (AttnRes), a breakthrough that fundamentally rewires how information travels vertically through a neural network. The researchers noticed a formal duality between this depth-wise accumulation problem and the sequential recurrence issues that plagued old Recurrent Neural Networks (RNNs) before the invention of the Transformer.
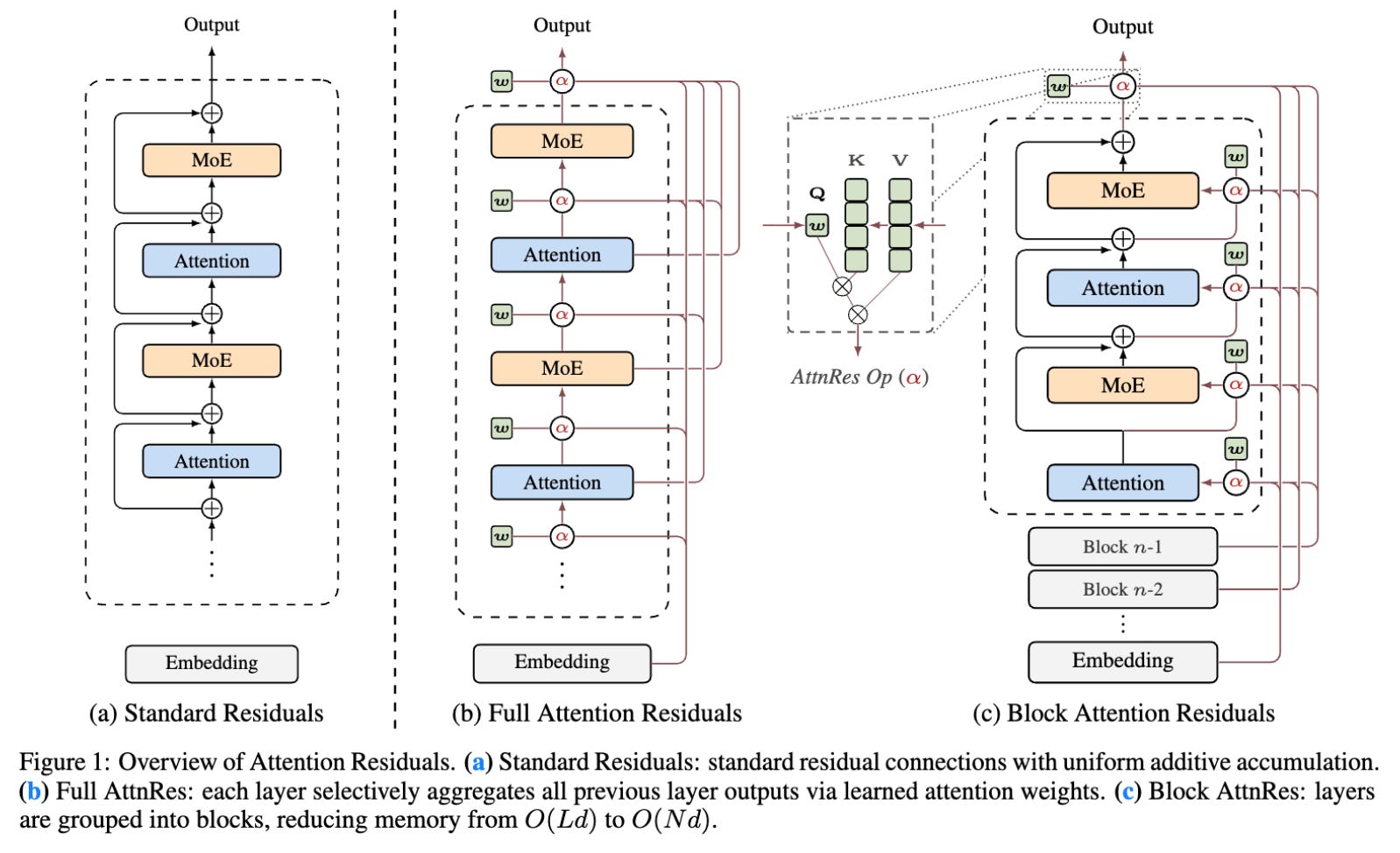
Just as the original attention mechanism allowed models to selectively look back at specific words in a long sequence, AttnRes allows a model to selectively look back at specific layers in its own deep architecture. Instead of the fixed, dumb accumulation of standard residuals, AttnRes uses a learned softmax attention mechanism. Every single layer is equipped with a single learned pseudo-query vector.
Think of this pseudo-query as a highly trained librarian. Instead of receiving a massive, unorganized pile of every book ever written by the previous layers, the librarian actively queries the archives. The layer can selectively emphasize crucial insights from layer 2 and entirely suppress irrelevant noise from layer 15. It is a lightweight mechanism that enables selective, content-aware retrieval across depth. This completes a transformative transition for network depth, mirroring the exact linear-to-softmax transition that revolutionized sequence modeling years ago.
But brilliant theory often hits a brick wall when it meets the brutal reality of large-scale model training. While Full AttnRes requires negligible overhead for standard training setups, modern frontier models are trained using pipeline parallelism. In a pipeline setup, saving all previous layer outputs and explicitly communicating them across different computing stages creates a massive bottleneck. The memory and communication overhead grows at an unmanageable rate.
To solve this scaling nightmare, the researchers engineered Block AttnRes. Instead of forcing every layer to look back at every single individual previous layer, they partition the layers into distinct blocks. Within each block, the outputs are summed together into a single representation. The cross-block attention is then applied only over these block-level summaries.

This is elegant engineering. By attending over a small number of block representations rather than every individual layer output, the memory and communication footprint drops drastically. The researchers combined this architecture with a brilliant cross-stage caching system to eliminate redundant transfers under pipeline parallelism. They also deployed a two-phase inference strategy that amortizes the cross-block attention computing costs. The inference latency overhead is impressively kept to less than 2% on typical workloads.
The empirical results are staggering. Scaling law experiments prove that AttnRes consistently outperforms the baseline architecture across all compute budgets. Specifically, Block AttnRes matches the loss of a baseline model that was trained with 1.25x more computational power.
To prove this works in the big leagues, the team integrated AttnRes into a massive 48-billion parameter Mixture-of-Experts architecture and pre-trained it on 1.4 trillion tokens. The training dynamics revealed that AttnRes completely mitigates the dreaded PreNorm dilution. The output magnitudes remain tightly bounded across the depth of the network, and the gradient norms distribute much more uniformly.
When tested on downstream benchmarks, this new architecture dominated the baseline. The improvements are massive in complex, multi-step reasoning tasks. It achieved a +7.5 point gain on the GPQA-Diamond benchmark and a +3.6 point gain on Minerva Math. It also showed significant boosts in code generation tasks like HumanEval.
By allowing later layers to precisely retrieve and build upon earlier representations, the model becomes vastly superior at compositional reasoning.
The Wrap-Up
If we no longer have to worry about the degradation of information across network depth, how much deeper and more specialized can our future AI architectures truly become before hitting the limits of silicon?
Compute Efficiency is Architectural: Throwing more raw compute at a problem is no longer the only way to scale capabilities. Block Attention Residuals act as a practical drop-in replacement for standard residual connections. Upgrading your underlying network wiring can yield the exact same performance as utilizing 1.25x more compute power.

Reasoning Capabilities Demand Better Retrieval: If your company is deploying models for complex coding or multi-step mathematical reasoning, standard architectures are actively bottlenecking your results. Providing layers with the ability to selectively aggregate earlier representations with learned weights dramatically improves performance on multi-step reasoning tasks. Future enterprise AI deployments must prioritize models capable of content-aware retrieval across their own depth.
You can see why this breakthrough has the AI community in an uproar.
Friends: in addition to the 17% discount for becoming annual paid members, we are excited to announce an additional 10% discount when paying with Bitcoin. Reach out to me, these discounts stack on top of each other!
Thank you for helping us accelerate Life in the Singularity by sharing.
I started Life in the Singularity in May 2023 to track all the accelerating changes in AI/ML, robotics, quantum computing and the rest of the technologies accelerating humanity forward into the future. I’m an investor in over a dozen technology companies and I needed a canvas to unfold and examine all the acceleration and breakthroughs across science and technology.
Our brilliant audience includes engineers and executives, incredible technologists, tons of investors, Fortune-500 board members and thousands of people who want to use technology to maximize the utility in their lives.
To help us continue our growth, would you please engage with this post and share us far and wide?! 🙏