
GLM-5.2 Proves AI Comes for All Moats
Bye, Bye, OpenAI?

I don’t want to get a reputation for overreacting to every new model drop.
Some of you will remember the piece I wrote about DeepSeek. Naval retweeted it, that got me invited onto a bunch of podcasts and speaking engagements, suddenly I became “the AI guy” and (forgive the cheese) it changed my life.
DeepSeek Proves AI Comes for All Jobs - Even AI Jobs

I don’t want to get a reputation for reactivity or hyperbolic statements.. but what just happened in the AI world (also the real world) changed the development trajectory of humanity.
And here we are again.
GLM-5.2 just came through the side door of the AI industry and kicked the whole building sideways.
Not because it is the undisputed best model in the world.
It isn’t.
Not because it ends OpenAI, Anthropic, or Google.
It doesn’t.
But because it changes the question.
The question is no longer: “Can an open Chinese model catch up to the American frontier?”
The question is now: “How much premium can the closed frontier labs keep charging once open models are this good, this cheap, and this deployable?”
Please read that again.
Because this is the part the market has not fully digested.
GLM-5.2 is not just another benchmark-chasing model release. It is a pressure event. It lands right in the middle of the OpenAI and Anthropic IPO narrative, right as public markets are being asked to underwrite trillion-dollar AI companies on the assumption that frontier intelligence remains scarce, closed, expensive, and defensible.
Then Z.ai shows up with a model that has a 1M-token context window, serious long-horizon coding ability, MIT-licensed open weights, local deployment options, and API output pricing around $4.40 per million tokens.
That is the wrench.
Maybe not a fatal wrench. But definitely a wrench.
The whole valuation story for the big Western AI labs depends on a simple belief: that the best intelligence will remain locked behind proprietary APIs and expensive subscriptions, and that enterprises will have no choice but to pay rent to the model gods.
GLM-5.2 attacks that belief directly.
It says: what if the frontier is not a castle?
What if it is a floodplain?
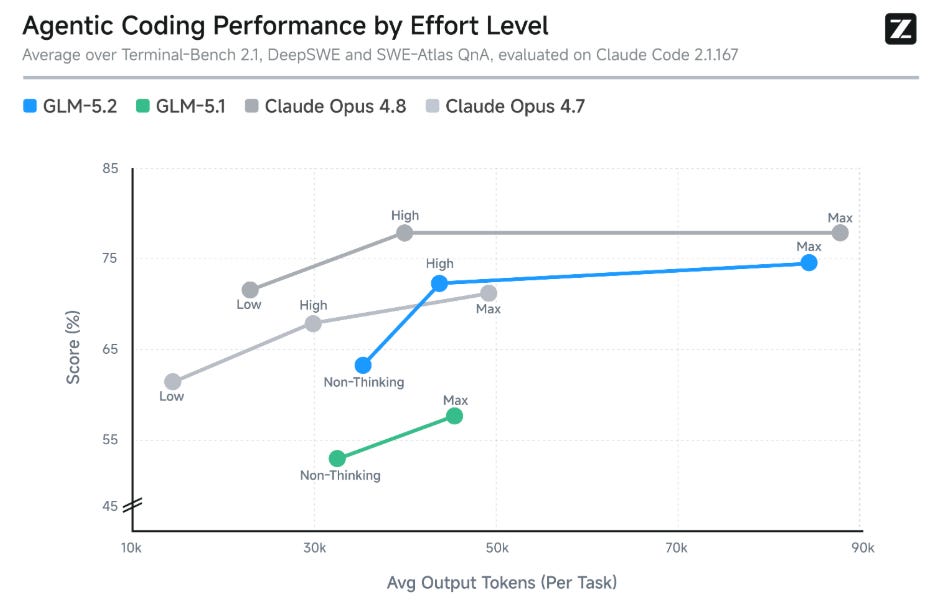
Z.ai’s own positioning is very clear. GLM-5.2 is built for long-horizon tasks. Not cute chatbot tasks. Not “write me a limerick about SaaS pricing” tasks. Real agentic work: codebases, multi-step engineering, long debugging loops, research reproduction, tool use, sustained execution.
That matters because coding agents are the first place where LLMs stop being toys and start becoming labor.
And GLM-5.2 is aimed directly at that market.
The model extends context from 200K to 1M tokens. But the more important claim is not “it can fit a million tokens.” Lots of people can slap a huge context window on a model and watch performance decay into soup.
The claim is that this is a usable million tokens.
That means a model can absorb the shape of a real software project: the architecture, the file boundaries, the API contracts, the weird historical decisions, the dependency constraints, the tests, the style, the hidden landmines, the things every senior engineer knows after three months and every AI agent usually forgets after twenty minutes.
That is not just “more memory.”
That is continuity.
And continuity is where software agents become dangerous.
A bad coding model can generate snippets.
A good coding model can solve issues.
A great coding model can hold a system in its head long enough to make coherent changes across time.
That is the ballgame.
This is why the benchmarks matter, even if we should never worship them. Z.ai claims GLM-5.2 is the top open-source model across several long-horizon coding benchmarks. On FrontierSWE, it trails Claude Opus 4.8 by about 1% while edging out GPT-5.5. On PostTrainBench, it ranks behind Opus 4.8 but ahead of GPT-5.5 and Opus 4.7. On Terminal-Bench 2.1, it posts an 81.0 versus GLM-5.1’s 63.5.
Again, benchmarks are not reality.
But they are not nothing.
They are smoke. And in AI, smoke usually means the fire is already spreading.
The real shock is the price-performance curve.
A model in the general neighborhood of closed frontier coding models, available for roughly $4.40 per million output tokens, with cached input pricing far below standard input, and open weights you can run yourself if you have the hardware.
This is not just cheap. This is strategically cheap.
This is “why exactly are we paying the frontier tax?” cheap.
This is the part that gets uncomfortable for OpenAI and Anthropic.
Their IPO stories need scarcity. They need the market to believe that intelligence is capital-intensive, yes, but also defensible. They need investors to believe the billions poured into compute create a moat that converts into pricing power. They need “we have the best model” to become “we have the best business.”
GLM-5.2 does not destroy that argument.
But it damages it.
Because every time an open model gets close enough, the premium model companies have to explain why “better” is worth 5x, 10x, or 20x the price.
Sometimes it will be.
For mission-critical tasks, enterprises will still pay for reliability, support, indemnity, governance, safety, integrations, procurement comfort, data controls, and brand trust.
But not always.
And “not always” is where valuations go to get humbled.
If you are a startup burning millions per year on inference, you do not need GLM-5.2 to beat Claude or GPT on every dimension. You need it to be good enough on enough workloads that your unit economics stop bleeding.
If you are an enterprise with sensitive code, you do not need the model to be the universal oracle. You need an option you can host, inspect, constrain, fine-tune, and govern.
If you are a developer using agents all day, you do not need religious loyalty to a logo. You need the model that gets the work done without turning your token bill into a second payroll.
That is the opening.
And it is wide.
This also quietly ruins the vibe around Gemini 3.5 Pro.
Google had its moment lined up. Gemini 3.5 Flash was pitched as frontier intelligence with action, strong agentic coding, long-horizon execution, and speed. Google said 3.5 Pro was coming next. The narrative was supposed to be: Google is back at the frontier, and Gemini is now the model family for agents.
Then GLM-5.2 appears with open weights, 1M context, serious coding benchmarks, and pricing that makes every closed model launch feel a little heavy.
That does not mean Gemini 3.5 Pro will be bad.
It may be excellent. In fact, I would be surprised if wasn’t. Google has absurd infrastructure, elite research talent, distribution everywhere, and a giant surface area across Search, Workspace, Android, Cloud, and everything else. Underestimate Google at your own risk.
But model launches are partly about narrative.
And GLM-5.2 stole oxygen.
It made “frontier agentic model” feel less like a sacred object and more like a category.
That is a huge psychological shift.
The Z.ai technical story is also not trivial. They are not just saying “we trained a big model and it got good.” They are talking about architectural efficiency. IndexShare reuses the same indexer across sparse attention layers and reduces long-context computational cost. They improved multi-token prediction for speculative decoding and increased acceptance length. They are explicitly optimizing the machinery required to make 1M-token work practical.
This is the deeper theme.
The frontier is not just about scale anymore.
It is about efficiency of intelligence.
Who can get the most capability per dollar, per watt, per GPU, per unit of latency, per developer hour?
This is where China has been terrifyingly strong.
DeepSeek showed the world that reasoning could be produced more efficiently than people assumed. GLM-5.2 continues the same pattern in the coding-agent world.
The uncomfortable American lesson is that constraints create invention.
If you have unlimited capital, unlimited GPU access, unlimited pricing power, and a customer base trained to pay premium rates, you can become lazy in ways that are invisible until someone hungrier ships around you.
China’s labs have been forced to optimize. Sanctions, compute limits, and market pressure created a different evolutionary environment. The result is not always the best model in absolute terms. But it is often the best model for the price.
And markets love price-performance.
They always have.
China = Copiers or Innovators?
Now, let’s take the countercase seriously.
Because there is one.
The harshest version goes like this: Chinese models are mostly distills of Western frontier models. They are downstream beneficiaries of OpenAI, Anthropic, and Google doing the expensive first-principles research. They are not creating the frontier at all. In fact they are just compressing it. Progress would stall if these labs did not have armies of VPN accounts hitting Western APIs from non-Chinese IPs, extracting behavior, generating synthetic data, and laundering proprietary intelligence into “open” models.
That argument is not crazy.
In fact, it is almost certainly true, in part.
Distillation is everywhere. Synthetic data is everywhere. Model outputs train other models. The whole field is eating itself recursively.
And yes, the American frontier labs may be doing the most expensive trailblazing. They discover the capability, absorb the failures, pay the compute tax, build the scaffolding, run the safety work, create the product category, and then others imitate the behavior at lower cost.
That is a real concern.
If every cheap open model is downstream of closed frontier labs, then the open ecosystem may be more dependent on the closed labs than it wants to admit.
The “Chinese models are just distills” critique is really an argument about originality, sustainability, and fairness.
Originality: did the model learn fundamental capability from its own training process, or did it learn to mimic the behavior of models that were much more expensive to create?
Sustainability: if Western labs stopped advancing, would these models keep improving or plateau?
Fairness: is this competitive innovation, or is it industrial-scale free-riding?
Those questions matter.
But here is the problem for the countercase: customers do not pay for metaphysics. They pay for results.
If a model solves the task, integrates into the workflow, runs locally, and costs a fraction of the alternative, the buyer does not usually care whether the capability came from pristine original research, clever distillation, open papers, synthetic data, reinforcement learning, or some blurry mixture of all of the above.
The market asks: does it work?
Then: how much does it cost?
Then: can I trust it?
The distillation argument may be morally and strategically important. It may influence export controls, lawsuits, procurement rules, and national security policy. It may absolutely shape how governments respond.
But it does not erase the competitive effect.
A cheaper substitute does not become less disruptive because its origin story is messy.
If anything, that makes the situation more destabilizing.
Because the American labs may be funding the frontier research that commoditizes their own products.
Loops and Curves
Spend $100 billion pushing the frontier.
Watch someone else learn from the exhaust.
Compete against their cheaper model.
Lower your prices.
Raise more money.
Repeat.
That is a brutal loop.
This is why GLM-5.2 matters beyond the model itself.
It points toward a world where frontier capability diffuses faster than frontier economics can stabilize.
The capability curve goes up. The cost curve goes down.
The moat duration shrinks.
That is incredible for builders.. and terrifying for anyone underwriting monopoly pricing.
I still think closed labs have advantages.
They will have the best multimodal systems. They will own premium consumer products. They will have enterprise trust. They will have the deepest research benches. They will build better safety layers, better tool ecosystems, better integrations, better memory systems, better orchestration, better evals, and better support.
Also, open models are not magic. Local deployment is only “free” after you buy or rent serious hardware. A 1M-token MoE model is not casually running. Operationalizing open weights takes engineering skill. Serving long context at scale is hard. Security is hard. Reliability is hard. Fine-tuning can make models worse. Quantization can change behavior. Enterprise support matters.
So no, this is not “OpenAI is dead.”
That is lazy.
The real story is subtler and much more important.
OpenAI, Anthropic, and Google are not being killed by GLM-5.2.
They are being repriced by it.
Their products may still be better.
But their scarcity premium is under attack.
And once scarcity premium compresses, everything changes: margins, growth assumptions, IPO multiples, enterprise negotiations, product bundling, compute strategy, and the speed at which model intelligence becomes a commodity input.
That last phrase is the one to watch.
Commodity intelligence.
Not dumb intelligence.
Not weak intelligence.
Commodity intelligence that is extremely capable, widely available, locally runnable, and cheap enough to disappear into every workflow.
That is a different civilization.
Because when intelligence gets cheap, people stop rationing it.
They put it everywhere.
They run agents against every repo, every spreadsheet, every compliance process, every sales motion, every research question, every personal goal, every operational bottleneck.
The world becomes saturated with cognitive labor.
This is what I meant when I wrote about DeepSeek. The important thing was not just “China made a good model.” The important thing was that the recipe for intelligence production was changing.
GLM-5.2 is another turn of that same screw.
DeepSeek proved reasoning could emerge with shocking efficiency.
GLM-5.2 suggests long-horizon agentic work is becoming open, cheap, and deployable.
That is a massive shift.
The future does not belong only to whoever has the biggest model.
It belongs to whoever can turn intelligence into leverage at the lowest sustainable cost.
And that is why this release feels so important.
We are watching the AI industry move from priesthood to power tool.
From “come worship at our API” to “download the weights and build.”
From subscription intelligence to ambient intelligence.
From closed scarcity to competitive abundance.
There will be lawsuits.
There will be export controls.
There will be safety panics.
There will be national security arguments, some very real and some very convenient.
There will be benchmark fights, distillation accusations, pricing wars, and a lot of people pretending they saw all of this coming.
But the direction is getting clear.
The frontier is leaking.
And once intelligence leaks, it does not go back into the bottle.
Thanks for reading Life in the Singularity.
This post is public, so feel free to share it with someone still underwriting closed-model moats like it’s 2024.
Friends: in addition to the 17% discount for becoming annual paid members, we are excited to announce an additional 10% discount when paying with Bitcoin. Reach out to me, these discounts stack on top of each other!
Thank you for helping us accelerate Life in the Singularity by sharing.
I started Life in the Singularity in May 2023 to track all the accelerating changes in AI/ML, robotics, quantum computing and the rest of the technologies accelerating humanity forward into the future. I’m an investor in over a dozen technology companies and I needed a canvas to unfold and examine all the acceleration and breakthroughs across science and technology.
Our brilliant audience includes engineers and executives, incredible technologists, tons of investors, Fortune-500 board members and thousands of people who want to use technology to maximize the utility in their lives.
To help us continue our growth, would you please engage with this post and share us far and wide?! 🙏