
Diffusion May Overtake Transformers in 2026

I’ve been alpha testing Google’s new Diffusion model. It is blazingly fast and increasingly powerful.
According to a recently released research paper that is making major waves, it’s also the solution to the data problem.
For the last five years, the entire AI industry has been operating on a simple, exhilarating, and terrifying assumption: Bigger is Better.
More parameters, more data, more compute. We’ve all been chasing the scaling laws, convinced that the next trillion-token dataset would be the one to finally unlock AGI.
As an investor, I see the bills.
As a builder, I see the pipelines.
And I can tell you the dirty secret that everyone at the top knows: We are running out of data.
High-quality, human-generated text on the internet is a finite resource. We’re already at the point of scraping the bottom of the barrel and the performance of our models is beginning to flatline.
The old recipe was simple: train a massive Autoregressive model like GPT on an “ever-growing corpora”.
This isn’t just a technical problem… it’s a barrier to progress. The entire multi-trillion-dollar AI revolution is predicated on a resource we are actively exhausting.
What happens when the new data runs out?
People are discussing synthetic data factories and using AI agents to create “realistic data” for the models. That feels like photocopies of photocopies to me. Not the solution.
Then, a few days ago, a paper dropped from a team at NUS and Sea AI Lab “Diffusion Language Models are Super Data Learners.”

It’s a direct answer to the single biggest problem in our industry.
The paper asks a revolutionary question: What if we don’t need more data? What if we just need to learn better from the data we already have? What if we could trade a scarce resource (new tokens) for an abundant one (compute)?
They didn’t just ask the question.
They proved it. And in doing so, they just handed the blueprint for the next generation of AI to every builder smart enough to read it.
Trading Brute Force for Deep Understanding
So, what did they actually discover?
To understand the breakthrough, you have to understand the fundamental prison we’ve built for ourselves.
The “Old Way”: The Autoregressive Prison
For years, we’ve been building AR models. Think GPT. These models work in a very simple, very strict way: they read left-to-right and predict the next word. That’s it.
This “causal” bias is their greatest strength and their most critical weakness.
It’s a strength because it’s compute-efficient. It’s a simple, fast, one-pass operation. But it’s a crippling weakness because it means the model only ever learns a shallow, one-directional version of language.
Let’s use an analogy. An AR model is like a student who crams for a final by reading the textbook once, front-to-back. They might memorize enough to pass the test, but do they understand the material? Do they see the deep connections between Chapter 2 and Chapter 10? No. They just know what word comes next. And once they’ve read the book, they’re done.
To learn more, they need a new book.
The “New Way”: The Diffusion PhD
The team challenged this entire philosophy. They revisited a different architecture: Diffusion Language Models (DLMs).
A DLM learns in a completely different, and frankly, brutal way.
Instead of just reading a sentence, it takes a perfect, clean sentence, and utterly destroys it. It shatters it into a corrupted mess by masking random tokens. Then, it gives that mess back to the model and says: “Fix it.”
The model’s job isn’t to predict the next word. Its job is to rebuild the entire original sentence from the noise, iteratively, step-by-step. This is “iterative bidirectional denoising.”
This process is a monster from a compute perspective. But it forces the model to learn things an AR model can’t even dream of. It has to understand grammar, syntax, semantics, and long-range context, all at once, from any direction. This is what the paper calls “any-order modeling.”
Think about the implications.
This is our new student. The DLM is the PhD candidate who takes that same textbook, tears out every single page, throws them in the air, and then spends a year reassembling the entire book from scratch, writing a dissertation on why every word, sentence, and chapter connects.
Which one has a deeper understanding of the text?
The “Aha!” Moment
Here’s the killer finding. The team ran a series of perfectly controlled experiments. They took a fixed, limited amount of unique data and trained both an AR model and a DLM on it, allowing them to train for many, many epochs (i.e., re-reading the same data).
The AR model, our cram-student, learned quickly and then immediately hit a wall. Its performance saturated. It had seen the book once and had nothing left to learn.
But the DLM, our PhD student, just kept going. It kept re-reading, re-corrupting, and re-assembling the same data, and its performance just kept climbing.
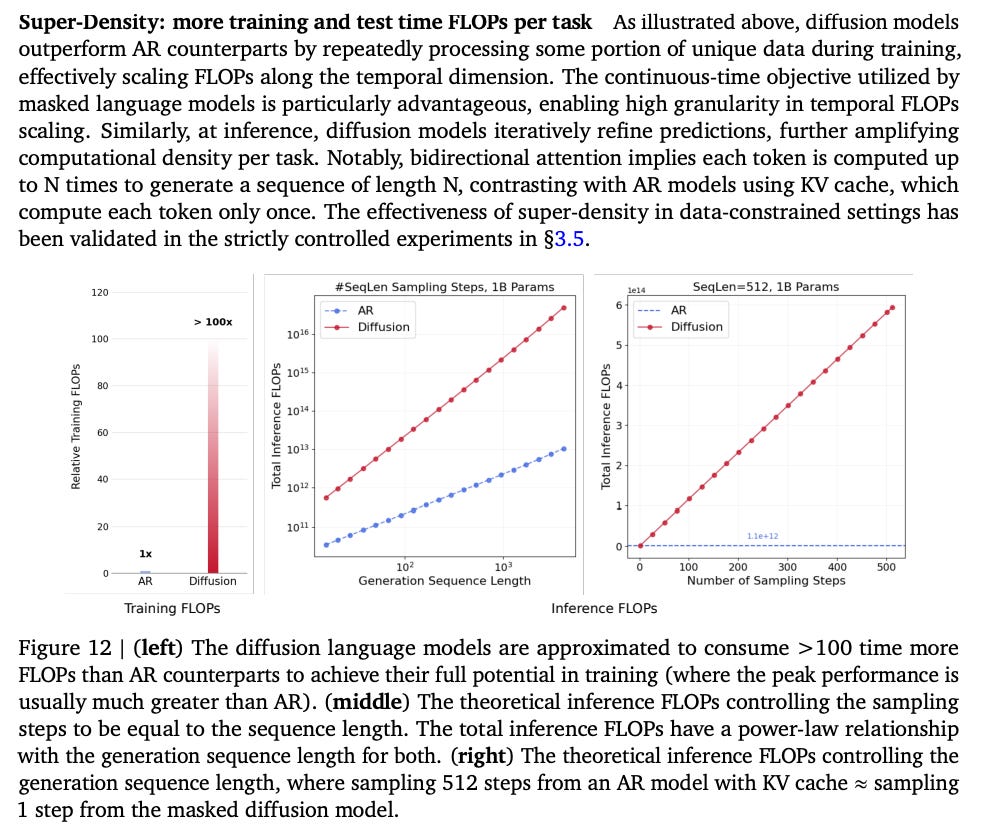
This is what they call “The Crossover.”
In a data-constrained environment, the DLM always surpasses the AR model.
The numbers are staggering:
3x Data Potential: They proved that a DLM can achieve the same performance as an AR model with one-third of the unique data. A DLM trained on just 0.5B unique tokens achieved parity with an AR model trained on 1.5B tokens. Let that sink in.
No Saturation: In their most extreme test, they trained a 1B DLM on just 1B unique tokens for 480 epochs. The AR models would have exploded into overfitting garbage. The DLM? It achieved an incredible >56% on HellaSwag and >33% on MMLU, and the performance curve was still going up. It hadn’t even saturated.
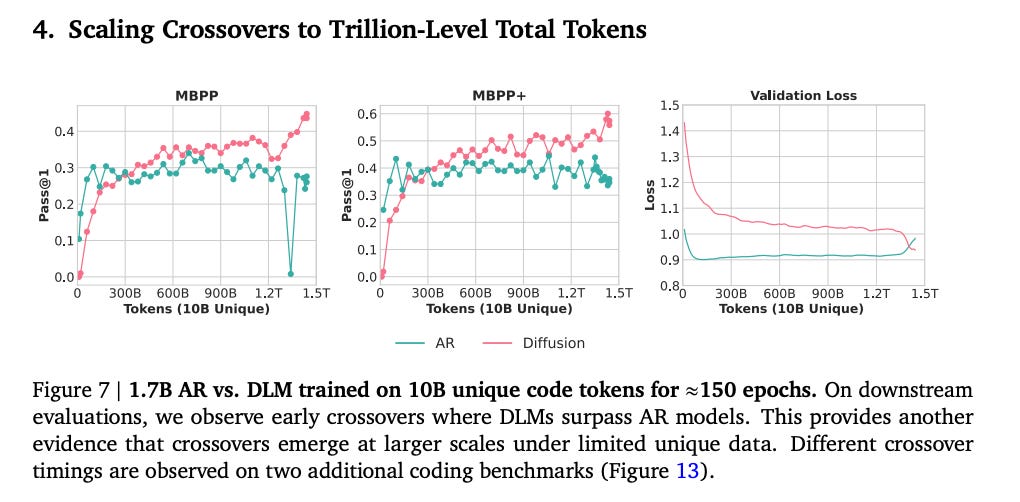
Real-World Proof: This isn’t a toy problem. They trained a 1.7B DLM on 10B unique Python tokens. They ran it for ~150 epochs (a ~1.5T token compute budget) , and it overtook the AR model trained on the exact same data and compute.
This is the “Aha!” moment. The bottleneck isn’t the data. The bottleneck is our method.
We’ve been using a cheap, efficient method (AR) that leaves much of the signal on the table. This paper proves that if we’re willing to spend compute, what they call “super-dense compute”, we can unlock 3x or more value from the exact same assets.
The ‘So What?’: An Asymmetric Opportunity
As an investor, this is where my hair stands on end. As a builder, this is where I start drawing up product specs. The market is pricing AI models based on the old playbook. The alpha is in understanding the new one.
This research fundamentally creates a new platform primitive.
The old primitive was “Next-Token Prediction.” It was a one-way street. Everything we built was a hack on top of this single, simple function.
The new primitive is “Iterative Refinement.” This is a universal assembler. Because the DLM isn’t bound by left-to-right causality, it can be applied to anything.
Code: Code isn’t “causal.” A function at the bottom of a file defines a class at the top. The paper proved this works for code. A diffusion-based coder won’t just complete your line; it will refine your entire block because it understands the full, non-causal context.
Science & Finance: Think protein folding, genomic data, or market movements. These are not left-to-right problems. These are complex, bidirectional systems. DLMs are tailor-made to find the deep structure in this kind of data.
On-the-fly Editing: An AR model can’t edit the middle of its output. It has to start over. A DLM is an editor. Its entire function is to “modify” context. This unlocks an entire new class of user interfaces.
The Great Market Disruption
This paper just reset the board.
WHO LOSES: Anyone whose entire business model is “we have a slightly bigger, scraped, multi-trillion-token dataset.” The data-hoarding-and-scraping economy just took a massive hit. The incumbents’ core advantage, their massive data moat, just got 3x smaller.
WHO WINS:
