
Deep Learning Is an Illusion: The Google Research That Just Rewrote the Rules of Scale
RIP Transformers: Why the Next Trillion-Dollar AI Won’t Be "Deep"

We need to have a hard conversation about the current state of AI.
I look at pitch decks every single day. I see brilliant founders raising $50 million seed rounds to train the next iteration of a Transformer. They are chasing scale. They are buying thousands of H100s. They are betting the farm that more layers and more tokens equal a better product.
They are wrong.
We are hitting a wall. It is not a compute wall. It’s a biological one.
Here is the dirty secret of the Large Language Model economy. We are spending billions of dollars to build static artifacts. We train a model like GPT-5 or Gemini 3. We freeze the weights. Then we deploy it.
From the moment that training run finishes the model is brain-dead. It cannot learn anything new.
It has “anterograde amnesia”.
It can process the text you feed it in the prompt. But it cannot form new long-term memories. It cannot evolve. It lives in an eternal present.
This is a massive capital inefficiency.
Imagine hiring a brilliant analyst who has read every book in the Library of Congress. But this analyst can never learn a new skill. They can never remember your name from yesterday. They can never update their worldview based on today’s news without a multimillion-dollar “retraining” surgery.
That is the “Old Way.” It is brittle. It is expensive. It creates products that degrade the moment they hit production because the world changes and the model does not.
I have been waiting for the signal that this era is ending. I have been waiting for the architecture that turns “static statues” into “liquid intelligence.”
Last week a team from Google Research dropped a paper called “Nested Learning: The Illusion of Deep Learning”.
It is dense.
It is mathematical.
It is heavy on neuroscience.
But I think its what I’ve been looking for.
If you read between the lines it is the most important signal I have seen this year. It effectively declares the current paradigm of Deep Learning obsolete. It proposes a new blueprint.
And it is not just a paper. It is the starting gun for a trillion-dollar market shift.

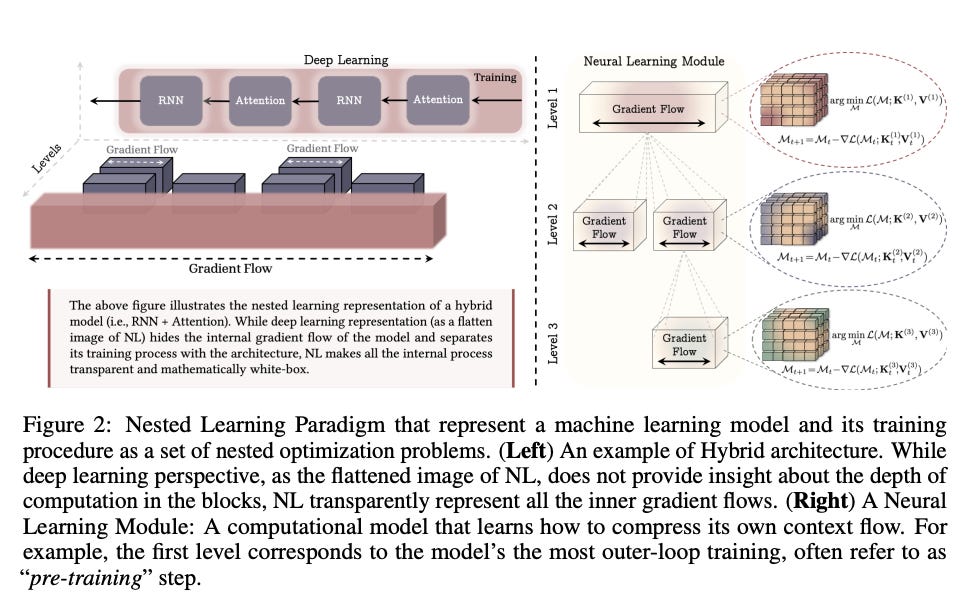
The researchers did something bold. They stopped looking at neural networks as stacks of layers. They started looking at them as nested loops.
Side Note: I LOVE when people are willing to look at the world differently and then have the courage to explore this undiscovered landscape.
The paper is titled “Nested Learning” (NL) for a reason. The core insight is that “depth” in deep learning is an illusion. We think we are building deep reasoning. We are actually just stacking shallow optimizations.
Speaking of dense, that sounds dense.. but I will unpack it all. And then go into the implications this has on the tech sector and business broadly.
Here is how the researchers from Google changed AI.
The Operating System of the Brain
The authors looked at the human brain.

The brain does not have a single clock speed. It has waves.
Delta Waves (0.5-4Hz): Slow. Deep. Long-term integration.
Gamma Waves (30-100Hz): Fast. Immediate processing.
Current Transformers run on one clock speed. Every layer updates at the same rate during training. It is inefficient.
It is unnatural. Every time man mimics nature, we get closer to perfect engineering. So it goes with our ML architecture.
Nested Learning proposes a “Uniform and Reusable Structure”. Instead of a messy stack of layers they decompose the architecture into specific levels. Each level has its own “context flow” and its own update frequency.
Think of it like a modern corporation. You have the CEO thinking in 5-year cycles. You have middle management thinking in quarterly cycles. You have the sales and delivery teams executing in daily cycles.
The NL paradigm builds models this way. High-frequency neurons handle the immediate tokens. Low-frequency neurons handle the long-term concepts.
The Optimizer is the Memory
This is the part that made me sit up in my chair.
As a builder I have always treated the optimizer (like Adam or SGD) as a tool. It is just the wrench we use to tighten the bolts (weights).
The paper flips this.
They prove mathematically that optimizers are actually associative memory modules.
When you run Gradient Descent you are essentially compressing the data into the weights. The optimizer is not just a tool. It is a learning component itself.
The authors show that “Gradient Descent with Momentum” is actually a 2-level nested learning system.
Level 1: The inner loop compresses gradients.
Level 2: The outer loop updates the slow weights.
They realized that if optimizers are just memory systems we can make them smarter. We can replace simple momentum with “Deep Memory.” We can use neural networks inside the optimizer to learn how to learn.
3. The “HOPE” Architecture
They didn’t just theorize. They built a machine.
They call it HOPE. It stands for a Self-Referential Learning Module with Continuum Memory.
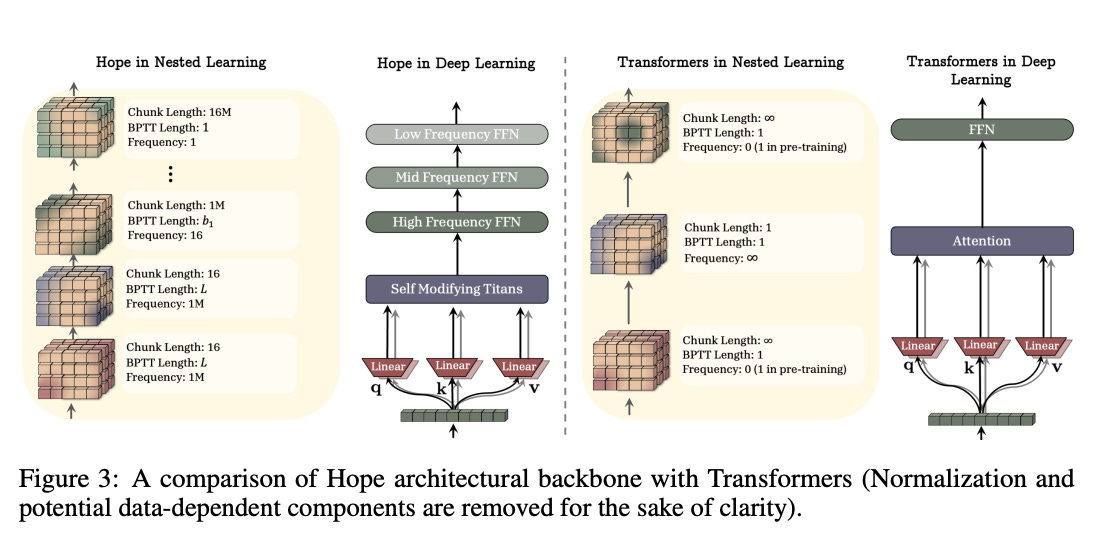
This is what it does:
Self-Modification: It uses a “Self-Modifying Titans” block. The model learns its own update algorithm. It rewrites its own code on the fly.
Continuum Memory: Instead of just “Long-Term” (weights) and “Short-Term” (context window) memory it has a full spectrum. It has memory blocks that update at every single time scale.
The Result
They tested HOPE against the best models in the world. Transformer++. RetNet. DeltaNet.
HOPE crushed them.
With only 760M parameters it outperformed models that were far larger on perplexity and reasoning tasks. But the raw score isn’t the point.
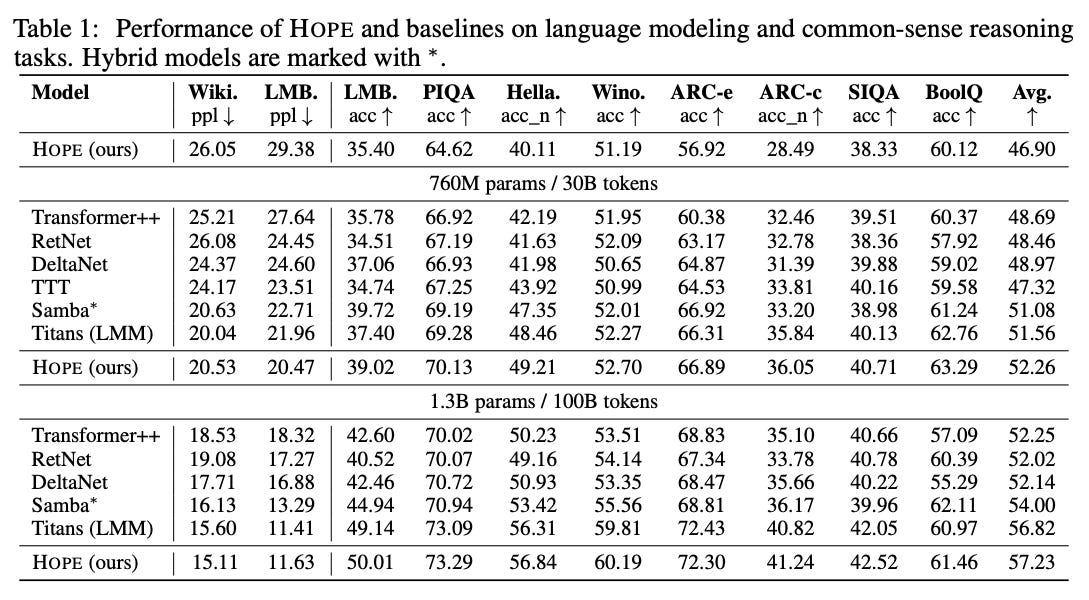
The point is how it won. It won because it mimics neuroplasticity. It reorganizes itself based on new experiences. It consolidates memory “online”.
This proves we can build models that learn continuously.
We don’t need to stop training.
The deployment is the training.
It’s learning as it goes, like we do!
The ‘So What?’: An Asymmetric Opportunity for Investors
This is where we leave the academic lab and enter the boardroom.
Why does this matter for your portfolio? Why is this an asymmetric bet? Which companies (or industries) are in better (or worse) shape because of this breakthrough?
1. The End of the “Context Window” Wars
