
Alibaba Cloud Computing Reinvented Reinforcement Learning

I love leverage, the fulcrum that lets you move the world with a small push. I look for leverage across all areas of my life.
First, it was using Python to find the hidden alpha in financial statements back when I worked on Wall Street.
Now, it’s about building and backing companies that embed AI into their DNA. I’ve seen firsthand that the raw power of machine learning is staggering, but I’ve also seen its Achilles’ heel: it’s an expensive, inefficient, and often brittle learner.
We’ve been training our most advanced AIs with the subtlety of a firehose, drowning them in data and hoping they learn to swim. It works, but it’s a colossal waste of energy and potential. We’ve been building digital calculators when we should be nurturing digital intellects.
That’s why, every so often, a research paper lands that feels less like an incremental step and more like a paradigm shift. It offers a new kind of leverage. The paper on VCRL, or Variance-based Curriculum Reinforcement Learning, is one of them. It’s a blueprint for a smarter, more elegant way to teach our machines, a method that could finally shift us from brute-force training to building truly expert AI.

The AI Gets a Personal Trainer
Imagine trying to teach a child calculus by having them memorize the textbook. They might pass the test, but they won’t truly understand the concepts. This is, in essence, how we’ve been training many of our most advanced Large Language Models, especially for complex tasks like mathematical reasoning.
The core problem researchers from Alibaba Cloud Computing tackled is that current reinforcement learning methods train AIs inefficiently. These methods throw a random assortment of problems at the model, failing to consider whether a problem is too easy to be instructive or too difficult to be anything but frustrating. It’s a one-size-fits-all approach that ignores the model’s evolving skill level.
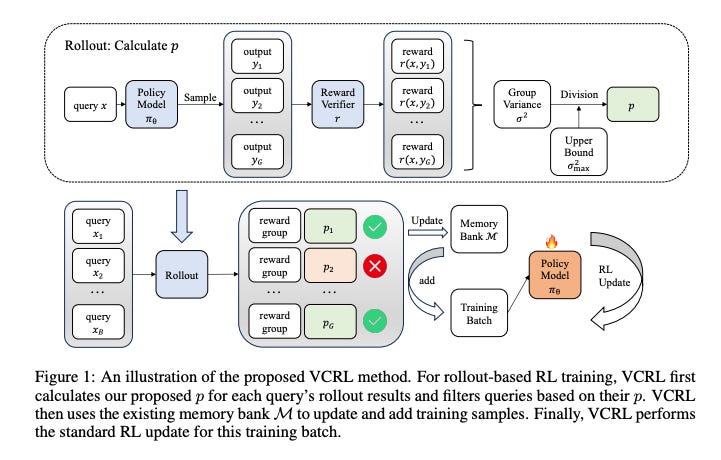
The authors’ brilliant solution is a framework called Variance-based Curriculum Reinforcement Learning (VCRL), which acts like an expert tutor for the AI. Instead of force-feeding the model random problems, VCRL first gauges the difficulty of a problem relative to the AI’s current ability. It does this using a simple insight: by observing the variance in the AI’s success rate over several attempts, it can find problems in the “Goldilocks zone”. If the AI succeeds every time, the problem is too easy (low variance). If it fails every time, it’s too hard (low variance). But if it succeeds sometimes and fails others, the problem is perfectly challenging, and the variance is high.
This is the sweet spot for learning. That’s where children learn the most, same thing with machines, it seems.
The key findings are nothing short of spectacular.
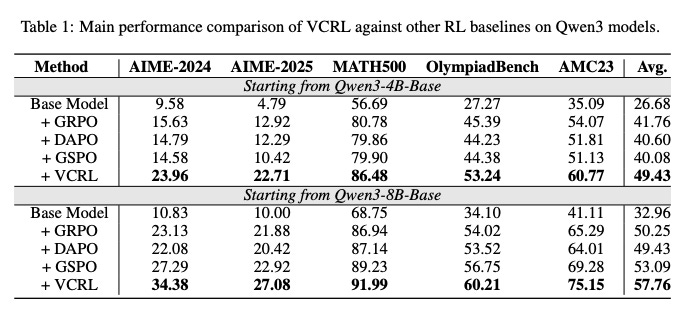
On five different mathematical benchmarks, models trained with VCRL consistently and dramatically outperformed those trained with existing state-of-the-art methods. They not only learned faster but also reached a significantly higher peak performance, especially on extremely difficult, competition-level math problems.
The single most significant contribution here is a new philosophy for AI training: we can create an automated, adaptive curriculum by listening to the AI itself. Variance is the signal of the model’s productive uncertainty, and by focusing the training there, VCRL ensures every computational cycle is spent on what matters most, turning an inefficient process into a highly optimized engine for intelligence.
From Brute Force to Finesse
For years, the field of AI alignment and training has been dominated by a brute-force mentality.
The prevailing wisdom was that with enough data, enough parameters, and enough computing power, intelligence would simply emerge. Techniques like Supervised Fine-Tuning (SFT) and later, Reinforcement Learning (RL), were born from this era. SFT is like giving an AI an answer key to memorize , while RL is like training a dog with treats—rewarding it for good outcomes. RL was a huge leap forward, especially with methods like Group Relative Policy Optimization (GRPO), which got rid of the need for a separate “value model” and allowed the AI to learn by comparing different attempts at solving the same problem.
But even these advanced RL methods, GRPO, DAPO, GSPO, shared a fundamental flaw: they were curriculum-agnostic. They treated the AI like a tireless factory worker, feeding it an unordered conveyor belt of tasks. There was no sense of progression, no understanding that what is difficult for a novice model becomes trivial for an expert one. This is incredibly inefficient. It’s like asking a grad student to practice basic arithmetic or a first-grader to solve differential equations. You’re wasting precious time and computational resources on tasks that are either uninformative or impossible, leading to slower progress and a lower performance ceiling. The field was stuck, knowing that a curriculum would be better but lacking a practical way to implement one that could adapt in real-time to a model that was learning and changing with every single update.
VCRL shatters this limitation with two key innovations.
The first, and most important, is using group reward variance as a dynamic difficulty metric. This is the breakthrough from my perspective. Instead of needing a human to label problems as “easy,” “medium,” or “hard,” VCRL lets the model’s own performance do the sorting. The assumption is revolutionary: the most fertile ground for learning is not consistent success, but structured struggle. The moments of highest variance, where the model is teetering on the edge of competence, are the moments of greatest learning potential. By prioritizing these high-variance problems, VCRL ensures the model is always being pushed, always operating at the frontier of its capabilities.
The second innovation is the Replay Learning with a memory bank. Calculating variance for every problem in real-time is computationally expensive. So, VCRL smartly creates a “greatest hits” collection of these perfect, high-variance problems in a memory bank. When the training process hits a batch of duds (too easy or too hard), it swaps them out for proven winners from the bank. This is an elegant engineering solution that makes the entire curriculum-based approach practical and efficient. This research fundamentally reframes the challenge of AI training. It’s no longer just about the quality of the data or the size of the model, but about the pedagogy aka the art and science of how we teach. VCRL provides the first scalable, automated pedagogy for machines, addressing the core challenge of training efficiency and unlocking a new level of performance.
Let’s lay out a super simple analogy:
Think of standard AI training as giving someone a generic workout plan from a website. It has a list of exercises and tells you to do 3 sets of 10 reps. For a while, you’ll get stronger. But soon you’ll plateau, because the plan doesn’t adapt to you. The weights are either too light to challenge you or so heavy you can’t even lift them.
VCRL is different. This method is an elite personal trainer standing right next to the AI. This trainer’s only goal is to maximize growth. They don’t care about the heaviest weight in the gym; they care about the right weight for you, right now. The trainer watches you lift. If you breeze through 10 reps without breaking a sweat, the weight is too light (low variance). If you can’t even move the bar, it’s too heavy (low variance).
The trainer is looking for that perfect weight where reps 8, 9, and 10 are a brutal, form-perfect struggle. That’s the high-variance zone, where your muscles are forced to adapt and grow stronger. VCRL is that trainer for the AI. It constantly measures the AI’s “struggle” through variance and ensures it is always lifting in that optimal growth zone, building its intellectual muscle as efficiently as possible.
And look how it outperforms all the other methods:
Specialist AIs
The implications of this work extend far beyond academic benchmarks. VCRL is a foundational technology that changes the economics and speed of creating highly capable, specialized AI systems. It’s a key that unlocks the next phase of the AI revolution.
In the near term, we will see an immediate impact on fields that rely on complex, logical reasoning. VCRL will drastically reduce the cost and time needed to train expert-level AIs for mathematics, programming, scientific research and most disciplines of engineering. Imagine an AI coding assistant that was trained not on all of GitHub, but on a perfectly curated curriculum of coding challenges that constantly pushed its abilities. Or a drug discovery AI that learns to navigate the complexities of molecular interactions through a VCRL-guided regimen. These specialized models will become more accessible to smaller companies and research labs, democratizing access to top-tier AI capabilities.
Looking further out, the core principle of VCRL, using variance as a proxy for learning-receptiveness, is almost universally applicable. This isn’t just a math trick; it’s an insight into learning itself. This opens up entirely new avenues of research.
Can this technique be adapted for creative tasks with subjective rewards, like writing or art generation?
What if we used variance to guide an AI’s exploration in robotics, teaching it to master complex physical manipulations?
The paper raises tantalizing questions: Could the shape of the variance curve over time become a “learning signature” that tells us about an AI’s unique cognitive strengths and weaknesses?
The practical applications are boundless. In my world of finance, we could train models to detect sophisticated fraud or build complex quantitative trading strategies with unprecedented efficiency. In medicine, VCRL could power the training of diagnostic AIs, feeding them a steady diet of patient cases that are perfectly calibrated to expand their knowledge. The most exciting application might be in education itself. The very principles VCRL uses to teach an AI could be used to build personalized AI tutors for human students, creating learning experiences that are always engaging and perfectly challenging.
Of course, the research has its limitations. The current implementation is demonstrated on tasks with a clear, binary reward, the answer is either right or wrong. The next great challenge will be to adapt this framework to domains with nuanced, multi-faceted outcomes. How do you calculate variance for the quality of a poem or the elegance of a legal argument?
Ultimately, what this research provides is leverage.
As an investor and a builder, I see VCRL as a tool that will fundamentally amplify our ability to create intelligence.
We are moving from an era of building generalist AIs to an era of cultivating legions of hyper-specialized digital experts. This paper provides the instruction manual. By teaching our machines to learn efficiently, we accelerate our own capacity for discovery and innovation. This is how we build a future where human intellect is partnered with a vast ecosystem of specialized AIs, together solving problems we once considered impossible.
That is a future worth investing in.
Friends: in addition to the 17% discount for becoming annual paid members, we are excited to announce an additional 10% discount when paying with Bitcoin. Reach out to me, these discounts stack on top of each other!
Thank you for helping us accelerate Life in the Singularity by sharing.
I started Life in the Singularity in May 2023 to track all the accelerating changes in AI/ML, robotics, quantum computing and the rest of the technologies accelerating humanity forward into the future. I’m an investor in over a dozen technology companies and I needed a canvas to unfold and examine all the acceleration and breakthroughs across science and technology.
Our brilliant audience includes engineers and executives, incredible technologists, tons of investors, Fortune-500 board members and thousands of people who want to use technology to maximize the utility in their lives.
To help us continue our growth, would you please engage with this post and share us far and wide?! 🙏