
A Strategic Analysis of Video Deep Research

The market is drunk on text.
We have spent the last three years obsessing over Large Language Models. We poured billions of dollars into optimizing the prediction of the next token.
We built cathedrals of syntax.
But we ignored the biological reality of intelligence.
Real intelligence is not text-based. It is sensory. It is the ability to witness a chaotic, visual reality, extract a singular signal, and execute a complex hunt based on that signal.
This is the difference between a library and a predator.
Most AI models today are librarians. They sit in a closed room, reading books (text training data) and answering questions based on what they have read.
They are safe. They are contained. They are fragile.
The paper before usVideo Deep Research: Watching, Reasoning and Searching is not an academic curiosity.
It is a blueprint for the evolution of the predator.
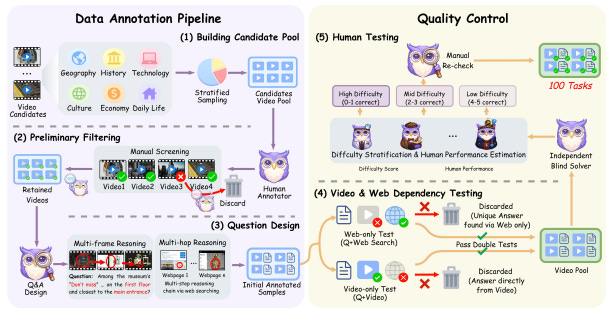
It describes the transition from “Closed-Context Perception” to “Active Evidence Exploration”. It details the shift from an organism that merely sees to an organism that hunts.
As an investor, I do not look for incremental improvements in accuracy. I look for the emergence of a new species.
This paper proves that the new species is here. But it also proves that it is currently brain-damaged.
Let’s dismantle the machine.
The Evolution of the Sensory-Motor Loop
To understand the alpha in this paper, you must first understand the metaphor of the Organism.
In evolutionary biology, the brain did not evolve to write poetry. It evolved to control movement. It evolved to process visual input (a predator) and coordinate a motor response (run or fight).
The current state of Video QA (Question Answering) is a lobotomy. The model watches a video. You ask a question. It answers from the video.
It is a closed loop. It is a reflex.
The authors of this paper have introduced a new stress test: VideoDR.
Here is the mechanism:
The Visual Anchor: The model must watch a video and spot a specific, fleeting detail. A registration number on a museum artifact. A sign in the background of a street scene.
The Hunt: The answer is not in the video. The model must leave the video, go to the Open Web, and perform a search.
The Synthesis: It must combine the visual memory with the web evidence to find the truth.
This is “Multi-hop Reasoning”.
It sounds simple. It is not.
It requires the model to maintain a “mental image” of what it saw while navigating the chaotic noise of the internet.
This is the exact cognitive function that separates a human from a golden retriever. A dog sees a squirrel (visual anchor). It runs. But if the squirrel vanishes, the dog forgets. It gets distracted by a smell. It loses the “Goal.”
Humans maintain the goal. We hold the image in our mind’s eye and pursue it across time and space.
This paper reveals that our best AI agents—even Gemini and GPT-4o—are closer to the dog than the human.
They suffer from “Goal Drift”.
They see the clue. They start the search. But three clicks deep into the web, they forget what they were looking for. The signal decays.
This is the “Goal Drift” bottleneck.
And this is where the money is.
The Battlefield: Workflow vs. Agentic
The paper presents two competing architectures for solving this problem.
This is the central conflict of the next five years of AI development.
1. The Workflow
This is the old world. It is safe. It is modular.
In this system, the model watches the video and immediately converts it into a text description. It translates the visual signal into a “structured intermediate text”.
It effectively takes notes.
Then, it throws the video away. It uses the text notes to search the web.
2. The Agent
This is the new world. It is volatile. It is powerful.
Here, a single multimodal agent ingests the video and the question directly. It does not take notes. It “thinks.” It decides when to search. It decides when to stop. It holds the raw visual data in its context window and iterates.
The Investment Thesis: Convention says “Agentic” is better. It is more advanced. It is “end-to-end.”
But the data in this paper screams the opposite.
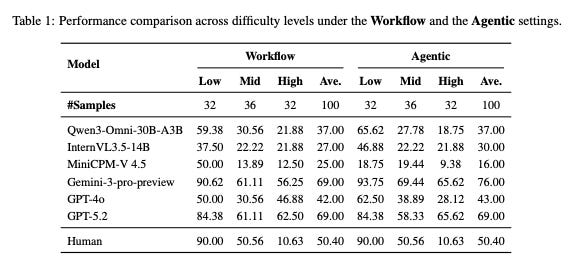
Look at the performance on “High Difficulty” tasks.
Gemini-3-pro (Agentic): 65.62%
Gemini-3-pro (Workflow): 56.25%
The Agentic model wins here. Why? Because the “Workflow” (taking notes) lost the subtle details. The text summary was too compressed. It missed the nuance.
But look at the mid-tier models. Look at GPT-4o.
GPT-4o (Agentic): 28.12%
GPT-4o (Workflow): 46.88%
This is a catastrophe.
When the task gets hard, the “advanced” Agentic model collapses. It drops by nearly 20 points.
Why?
Because it hallucinates. It drifts. Without the hard constraint of the “text notes,” the Agentic model gets lost in the noise of the open web.
The “Workflow” externalizes memory. It forces stability. The “Agentic” relies on internal focus.
The Lesson: Intelligence without endurance is useless.
The Agentic model is a genius with ADHD. It notices more, but it achieves less because it cannot stay on target.
The Workflow model is a bureaucrat. It misses details, but it finishes the job.
As an investor, I am not betting on the Bureaucrat. I am betting on fixing the Genius.
The opportunity lies in solving the “Long-horizon Consistency” of the Agentic model.
